The block-paved path to structured data
How block-based interfaces can help us create more structured data on the web
June 17th, 2022


This is a talk I first presented at Sanity's Structured Content Conference in May 2022 in San Francisco.
It's about the dream of creating more structured data on the web, the rise of block-based interfaces, and how those two intertwine. After covering a bit of history on structured data, I discuss the costs and benefits of block-based interfaces, and finally I introduce a new protocol we've been working on at HASH. It's called the Block Protocol and it hopes to solve a number of issues with both structured data on the web and block-based editors.
Here's the original video recording. You can also read the full written version and see slides below.
Video
Transcript and Slides



I like to give the punchline away early in my talks. I'm here to convince you of a thesis – that block-based interfaces can help us create more structured data on the web.

We're going to tackle this in four parts; we'll first clarify why we should care about structured data at all. We'll then look at the rise of block-based interfaces – a design pattern that's become incredibly popular over the last 5 years. We'll then consider some current problems with block-based interfaces. And finally we'll explore a protocol that we've been working on at HASH. The goal of it is to address many of these problems both with blocks and structured data.

First, why is it worth dreaming about a world where we have more structured data than right now?

“Structured data” means different things in different contexts, but in this talk I'm specifically going to be talking about structured data on the web.
The web is filled with content – blog posts, product descriptions, images, headlines, videos, and more. But for the most part, our computers have no clue what that content is about. That's because it's unstructured, meaning we haven't labeled the content in a way that makes sense to computers. In short, this content doesn't have good, standardized metadata.

So if I wanted to search the web for content on Ted Chiang's book Exhalation (a great read, by the way)...

And I do a standard text search for “exhalation”, I'll get some results about the book. But I'm just as likely to get results about breathing techniques or medical issues. The computer doesn't know the difference between Exhalation the book, and exhalation the biological concept. But we can fix this...
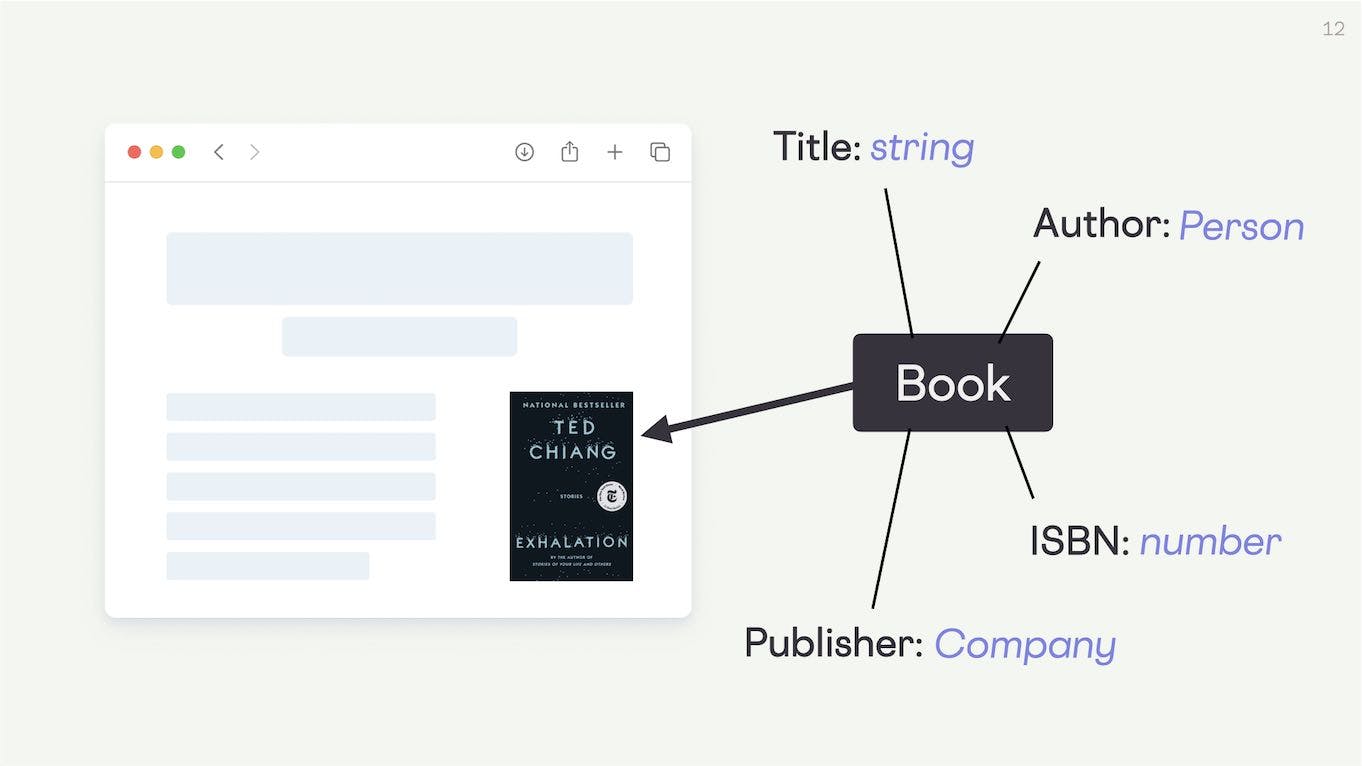
...by adding structured data. This simply means labeling this content in a way computers can understand. We can programmatically declare a type on it.
In this case, we would declare the type “book” and declare its properties and their expected types. So we would expect a book to have a title which is going to be a Text string, and an ISBN number, which is going to be a Number.
We typically call this type of structure a schema – it's a data format describing a human concept (such as Book, Person, Movie, Recipe) that declares a set of expected properties and their types.
Some of these properties will be types that have their own properties. For examples, the author which is of the type Person. Person is going to have properties like a name, a birthday, a job title. Similarly, the property publisher is going to be of the type Company.

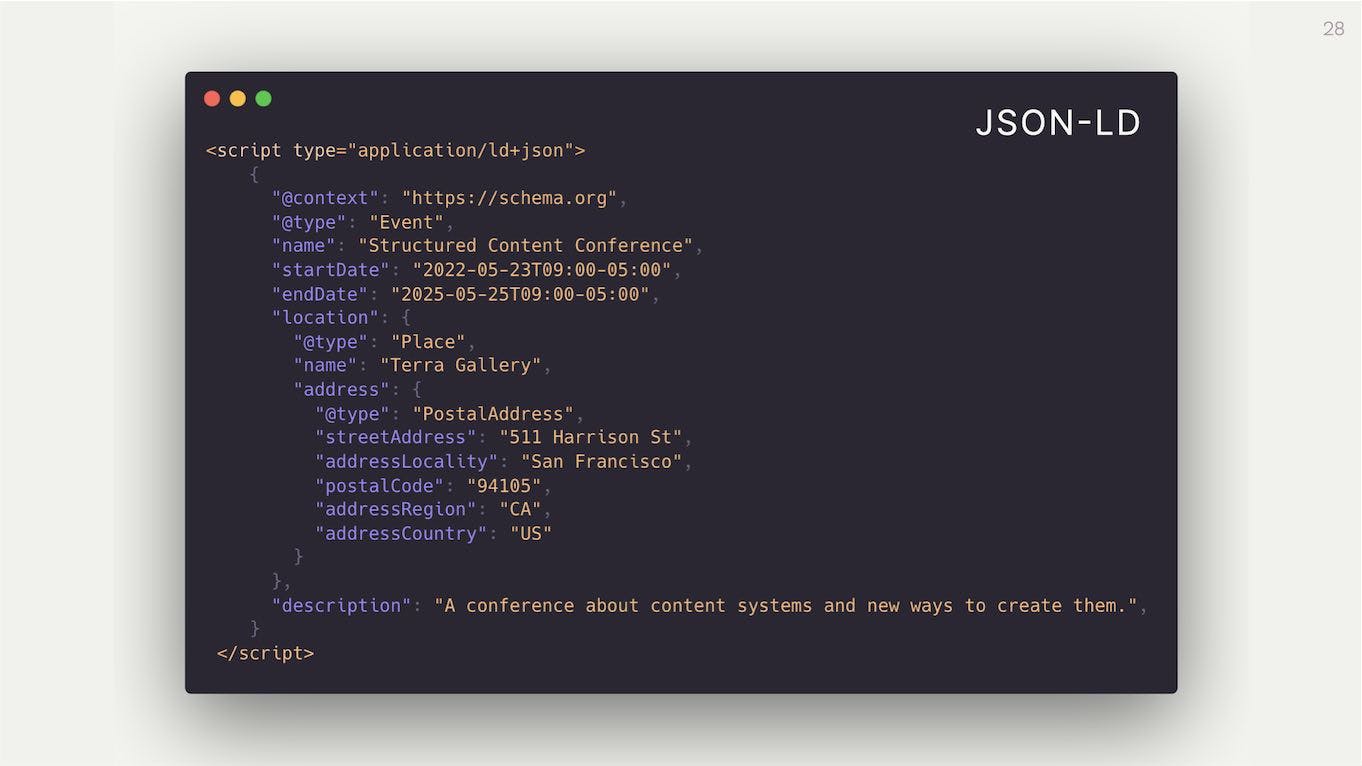
To give you a practical example of what this looks like, this is what unstructured data might look like for a website about this conference. We have the title in an <h1> tag and the description, times, and location in <p> tags.
As far as the computer knows, this content is a bunch of mystery nonsense. It's human-readable but not machine-readable.
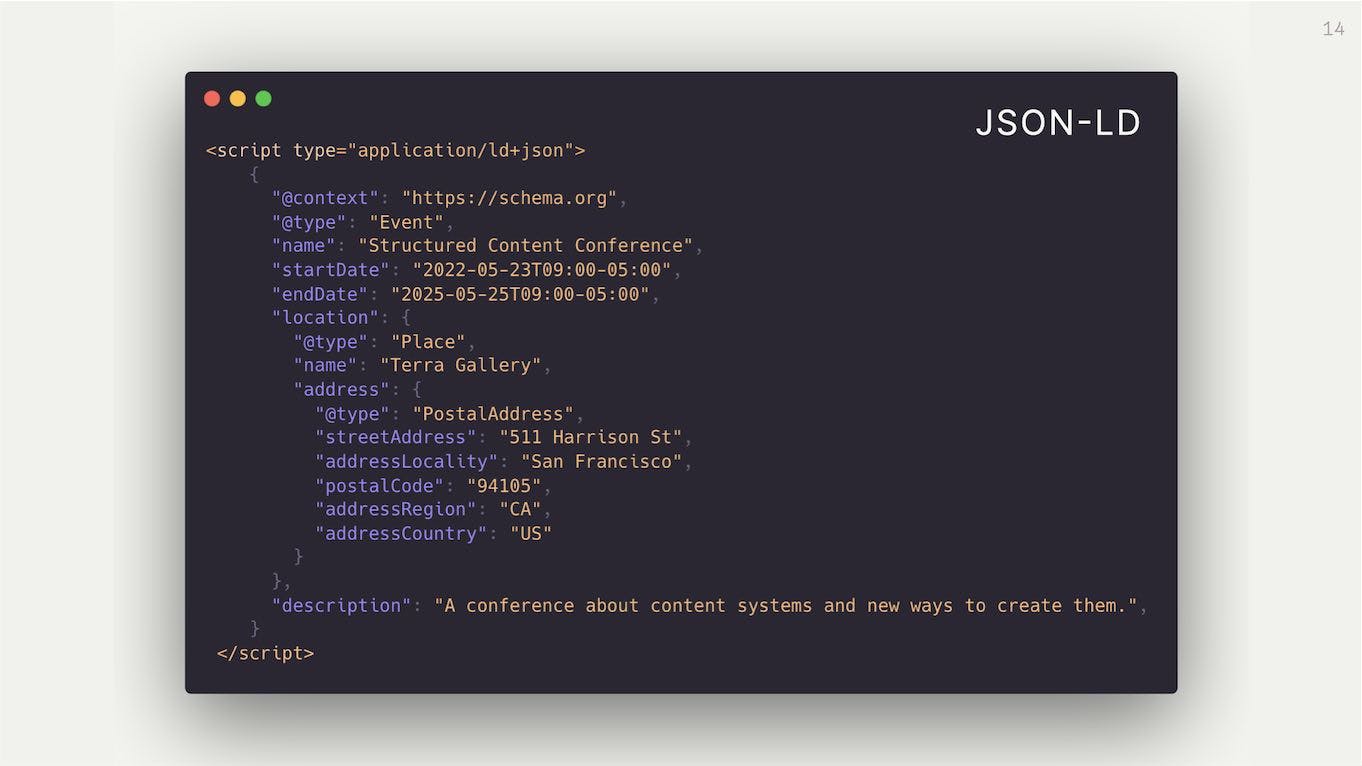
In contrast, this is what it would look like as structured data. This is the same event written up in JSON-LD (JSON Linked Data), which is currently the most popular and widely used format across the web.
We can see it declares that this thing is of the type Event, and has properties like a start date and an end date. It also has a location which is of the type Place, which in turn has an Address.

At this point, some people are thinking this all sounds very familiar. What I'm describing is the semantic web.
The semantic web is a dream that began over 20 years ago when Tim Berners-Lee wrote an article describing the possibilities of a web that could be read by machines.
This dream, that the whole web would become interoperable structured data, promised a bright future of frictionless automation and rich user experiences.
It's a beautiful dream, but to put it lightly, it's become complicated. The dream is enormously ambitious. And it's run into a number of problems since the original proposition.
At this point I'll say I'm not a semantic web expert, and this is a very touchy area, so I'll tread lightly. But there are a number of well known issues most people agree upon...

First, ontologies – meaning the schemas we define for types like “Person” or “Book” – are always culturally relative and subjective. There is no universal single set of properties we can all agree upon. This is because human culture is inherently pluralistic. That's perhaps the whole point of human culture. It's a mechanism to create wildly diverse ways of seeing and being in the world. So diverse it makes it impossible to agree on fundamental categories and properties for what exists around us.
Take the type “Person” for example. On schema.org, the largest and widely used repository of schemas (maintained by Google), a Person has the properties first name and last name. But in a great many cultures, people do not have first and last names. That's not how they name people. People may have multiple personal names, family names, and clan names that change depending on who is addressing them and in what context. None of these fit neatly into two boxes on a form.
Similarly, the type Postal Address might seem like something with a rigid structure. In places like the United Kingdom, we have strict formats for house numbers, street names, and postal codes. But in some places, street addresses have not been standardized and formalized by their governments. Someone's address might be “go 200 meters past the temple and it's the fourth house on the left.” Try putting that into your schema.

The second issue is competing formats. Over the years people have proposed many different ways to implement structured data on the web. There's RDF and RDFa, JSON-LD, and Microformats
Then there are all the annotation frameworks, query languages, and vocabularies that interact with these formats like OWL, FOAF, SPARQL, Turtle, and more.
You are probably overwhelmed by that list, and so are all the developers who are supposed to use them to make the dream of the semantic web come to life. It's not surprising most developers don't bother adding structured data to their sites.

Third, there are incentive issues. It takes a lot of developer labor to add semantic markup to a website, and doesn't offer immediate benefits in return. Structured data can certainly improve SEO and content discovery, but beyond that we haven't found enough compelling use cases for it for creators and publishers.

Lastly, the ambitious scale of the semantic web compounds all the above problems. Trying to structure data across the entire web leads to issues of complexity.
All these problems have made a lot of people skeptical about the feasibility of the semantic web. They're quite keen to throw the baby out with the bathwater.

The debate about the semantic web has devolved into an unhelpful binary.
On one side we have people insisting that structured data on the web has failed and will never work.
And on the other side we have people who are adamant that we need to fulfill the dream of a fully semantic web.
This conversation doesn't leave a lot of room for nuance.
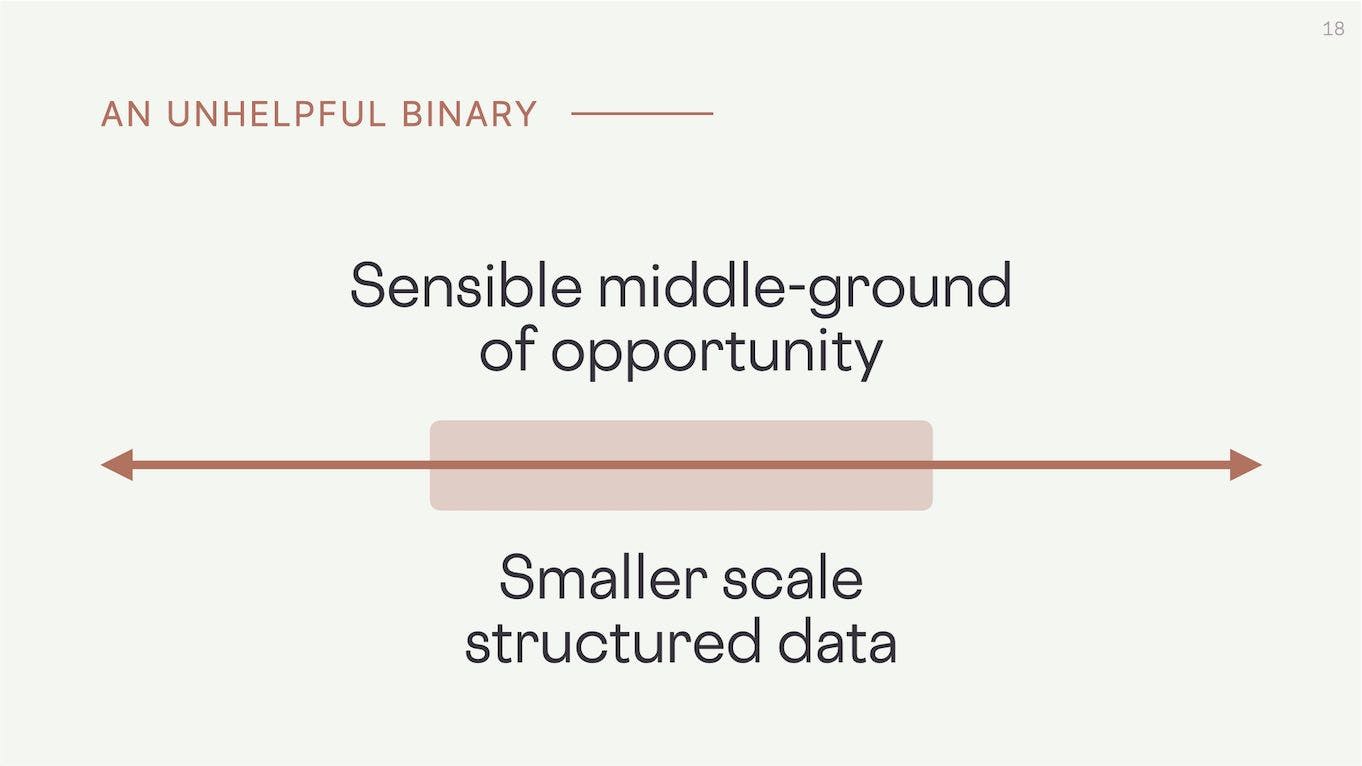
What we're missing here is the sensible middle ground of opportunity. There's plenty of value in pursuing structured data at a smaller scale. It's much easier to agree upon and maintain ontologies within companies, sets of companies, academic institutions, and communities.
The original idea wasn't the problem, only the scale of it.

Structured data is clearly useful. In fact, it's already actively used and useful across the web now. The most common use case you've likely heard of is around enabling SEO and “rich results” in search engines.
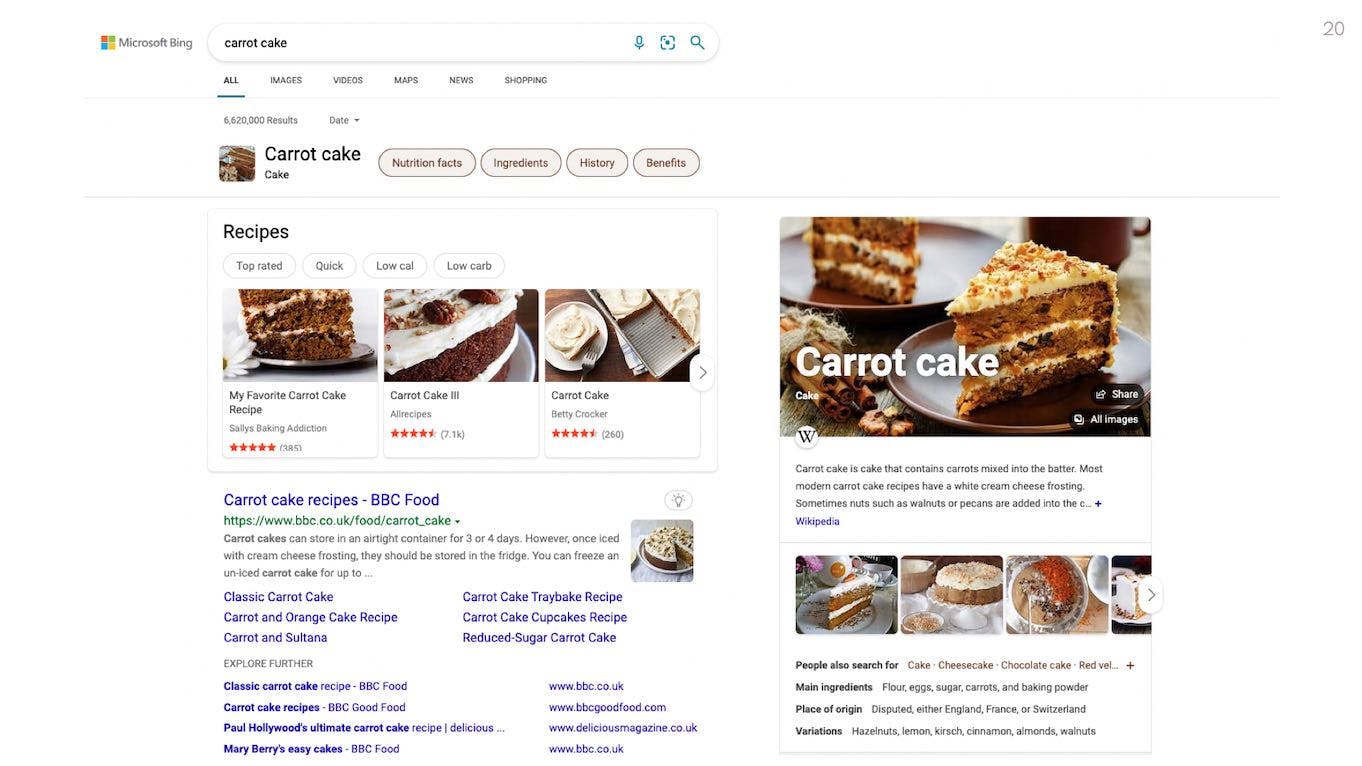
If I search for a recipe like “carrot cake” on the search engine Bing, I get a page filled with useful information like images, ratings, keywords, and Wikipedia data. All without needing to navigate to individual results pages. This is a much better experience than seeing a wall of text.
Bing knows which sites contain carrot cake recipes and can surface details from those recipes because they contain structured data.
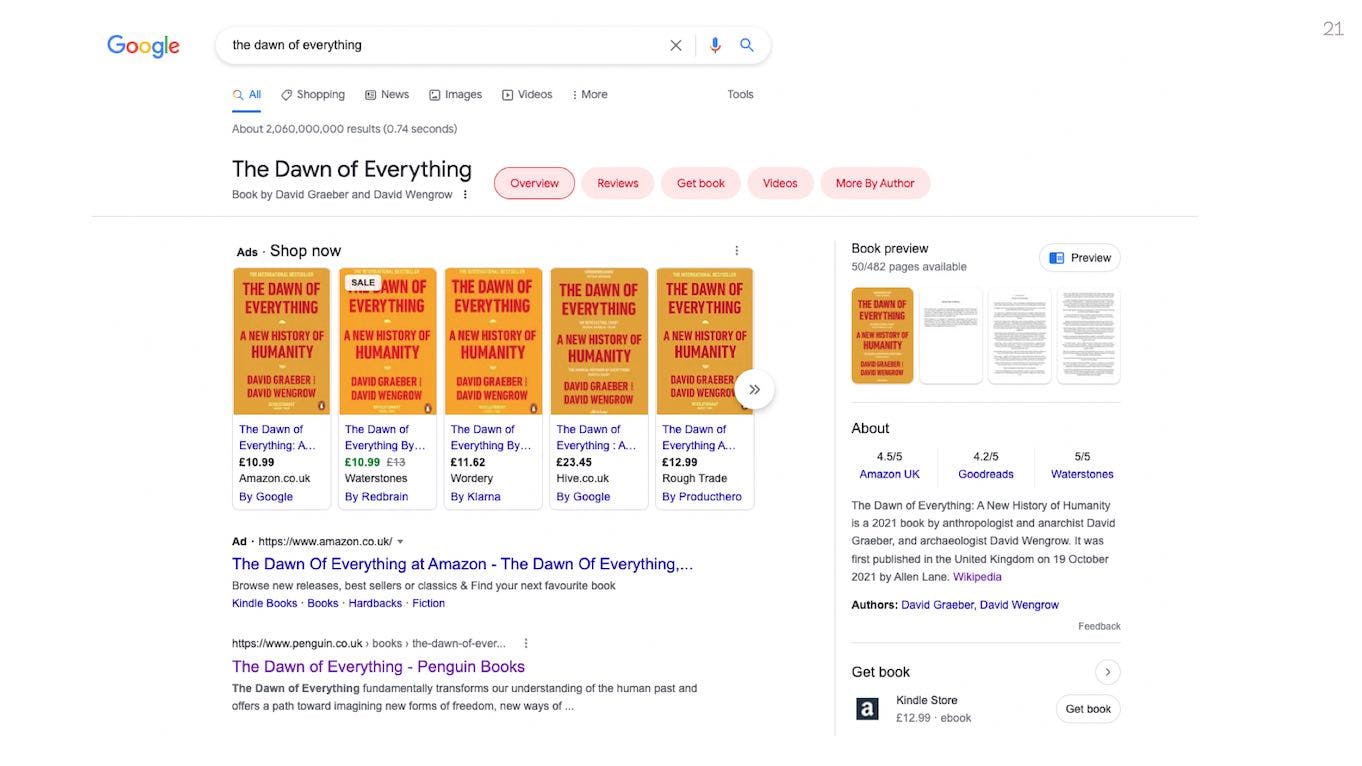
Similarly, if I search for the book “The Dawn of Everything” on Google, I get page showing me key information about the book. But I also get a row of options for where to buy this book and how much it costs.
Which means Google knows the difference between sites that are simply mentioning or reviewing this book, versus which ones are selling it as a product. This distinction is only possible because of structured data.
Search results are perhaps our best modern success story of leveraging structured data in user interfaces.

Second, structured data can help us manage content in a way that leads to adaptable, more sophisticated UX. This use case is what most of the people at this conference are focused on.
Structuring content just within a single company can lead to enormous benefits. Tools like Sanity are one way to do this. It allows us to adapt and reuse content within many contexts.
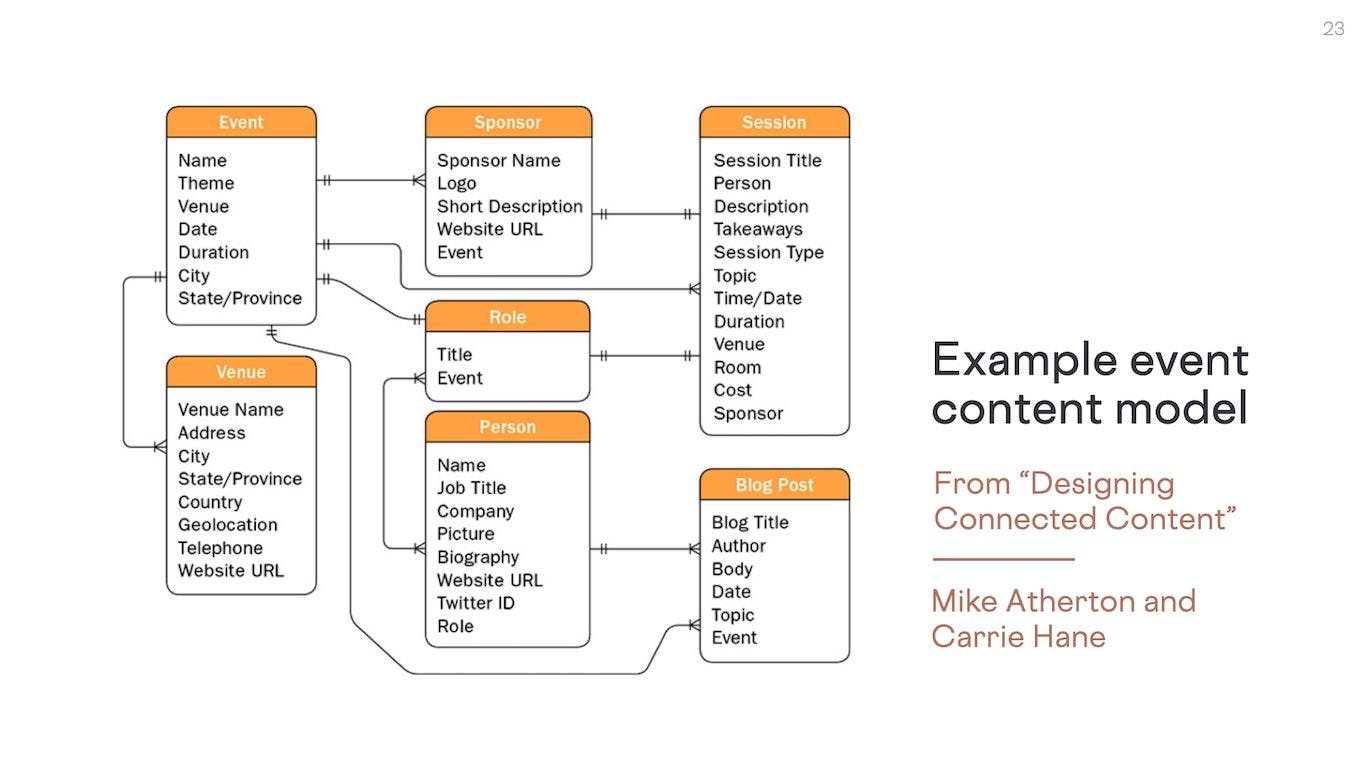
This is an example of a content model from the book Designing Connected Content. It shows a set of entities, properties, and relationships related to an Event type. This sort of structured content modeling allows us to create interfaces that provide users with a clear mental model of the things they're interacting with. It also makes it easy to define these pieces of data in one central place and flexibly reuse them across devices, platforms, and contexts.

Lastly, structured data makes life much easier for data scientists and academics. Data scientists in particular have trouble getting good quality data off the web. They often have to scrape websites, download messy data files, then manually clean, label, and format the data before they can work with it. Structured data eliminates much of that work.
There's also a lot of interest from the academic community around “knowledge graphs”, which are structured ontologies they use to share knowledge within specific domains.
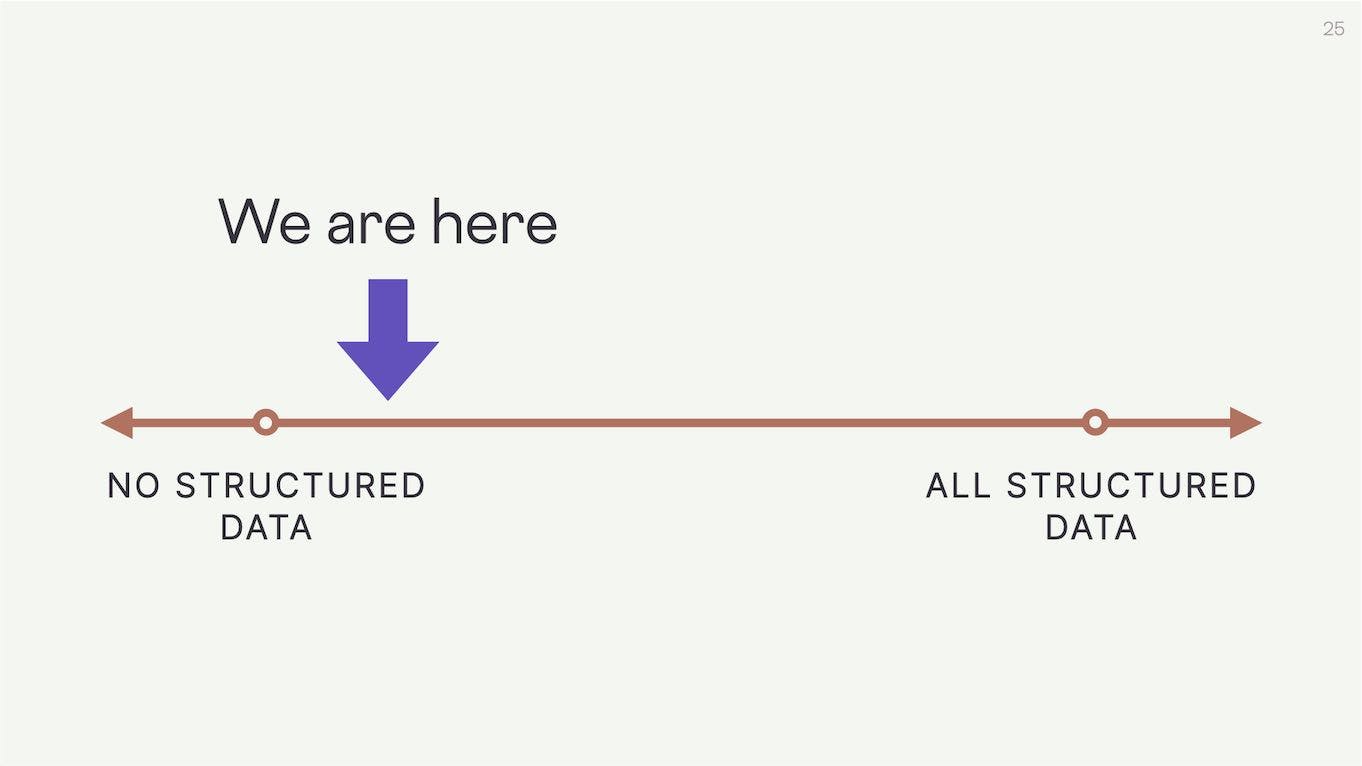
Let's jump back to our structured data binary for a moment. Right now we're about here on the spectrum of no structured data to all structured data. A very small percentage of content on the web is encoded with structured data.
We also don't have a lot of accessible, high-quality software that helps us create and publish more structured data.
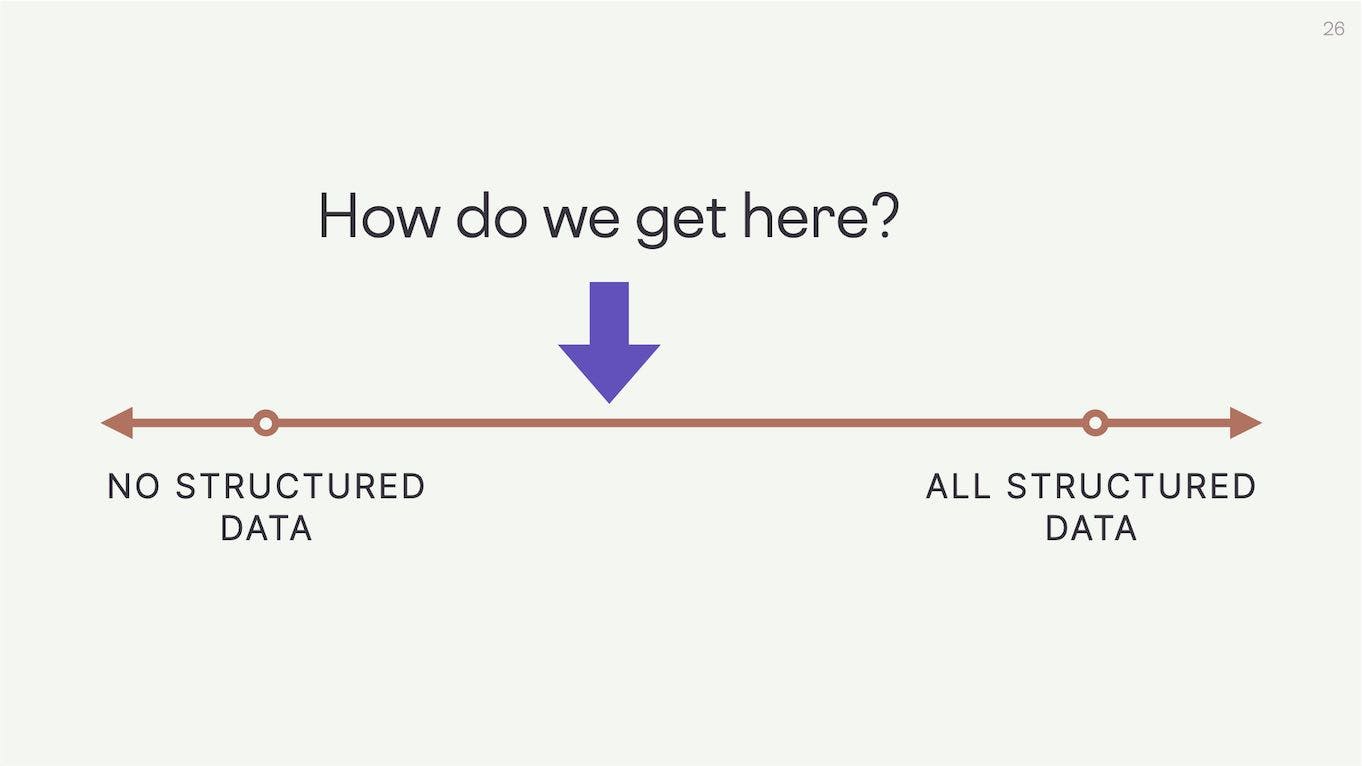
I think a practical question we should all be asking is how do we get here? Rather than trying to make the whole web structured data, how do we simply nudge this arrow slightly further along to the right?
The goal is more structured data, not all structured data.

One of the major barriers to this goal is that almost all our existing tools related to structured data are designed to serve developers.
Most of the focus of the semantic web movement has gone into creating syntax formats like RDF, OWL, and JSON-LD. There's also been a lot of effort put into convincing developers to join the cause. Rather than other people who are involved in making content on the web, like designers, product people, and content strategists.
And this is a really rough user interface to work in. And it's certainly not accessible to most people.

Which brings us to a prescient question: how do we make it easier for everyone to create structured data?

Or put more specifically, what type of interfaces might enable non-developers to create structured data?

So, I have a hypothesis for this question. And you can probably guess what it is... blocks!

I now want to talk to you about the huge surge in blocks and composable interfaces we've seen over the last five years.
But first, what exactly do I mean by a “block”?
Well, you have almost certainly seen and used a block.
This is a video - click play on the slide
Most of you will have encountered blocks in knowledge-management apps like Notion, which have (arguably) been responsible for a huge boom in awareness and popularity of blocks.
This is what the interface looks like. You begin on a page, type the slash command, and a menu appears where you can select a block from a list of pre-made formats. Such as a header, bullet point list, or a table. You can then enter data into that block and change the state of it. You can drag and drop these blocks around to arrange them however you like, including in side-by-side columns.
You're essentially able to create very powerful layouts and formats with a very simple set of interface patterns.
This is a video - click play on the slide
To show another example, this is Coda, a somewhat more advanced block-based editor. You can see here they have quite a long list of block types to pick from.
I can embed rich media like tweets, or query an external API like that of the Unsplash image library. All from within a friendly set of user interface components, and without writing any code.
This might not seem that impressive to you. We've become slightly jaded about these type of interfaces; WYSIWYG direct manipulation interfaces are taken for granted. But creating something like this would have been prohibitively complex just 5 years ago.
This is all very difficult to do if you're working in native web languages like HTML, CSS, and JS. For people who don't know how to code, block-based interfaces allow them to author rich media documents and publish them to the web in a couple of clicks. They're a huge leap forward in democratizing web publishing.
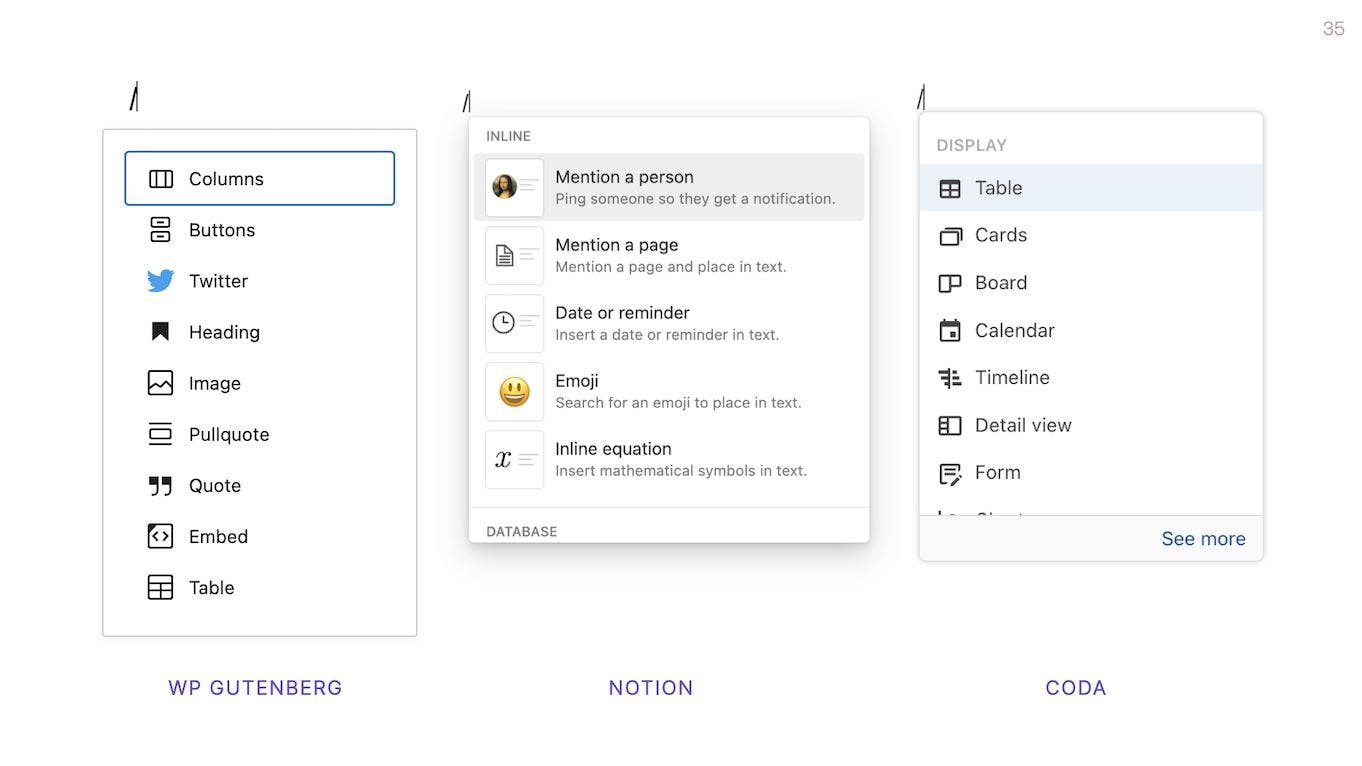
The interface patterns in block-based editors have already become quite consistent and standardized. In most of them you can type / and get a dropdown list of block options.
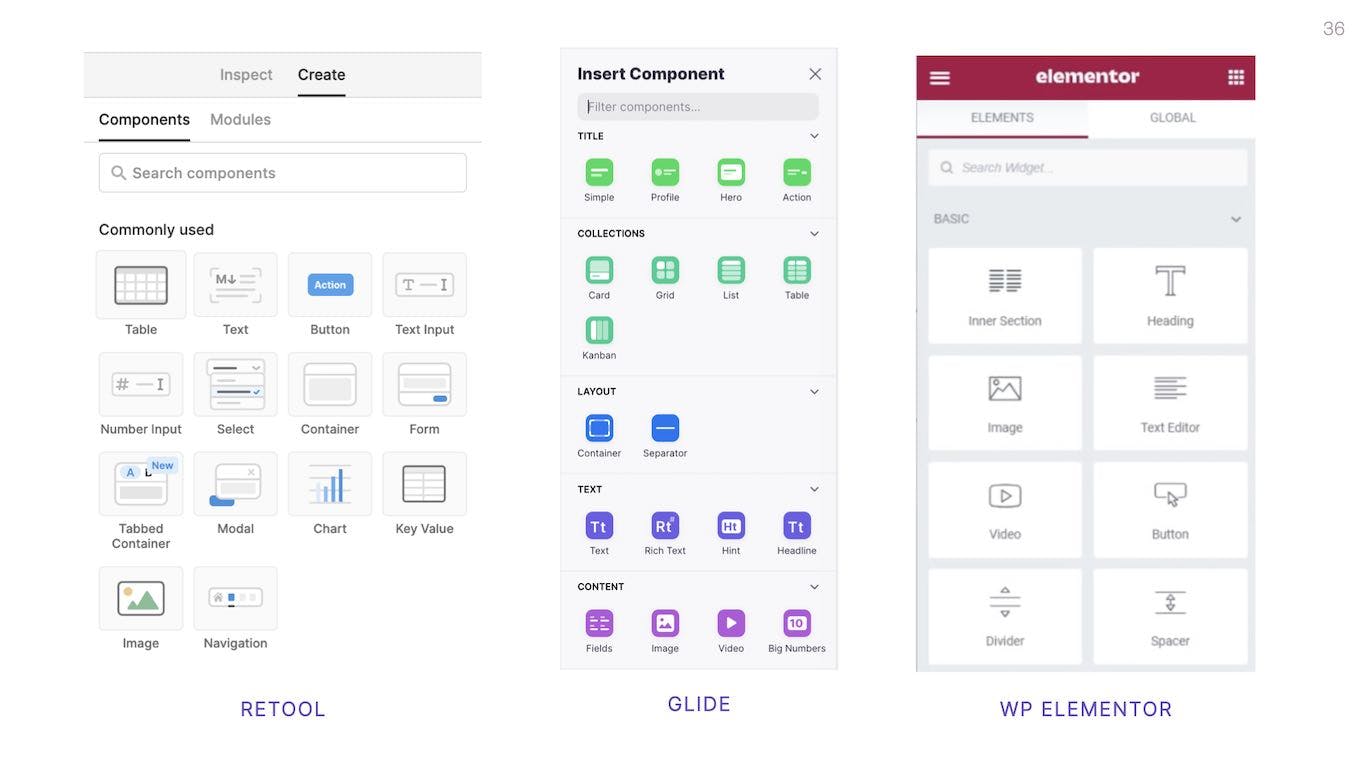
In some of the more complex ones, they present blocks in a sidebar or configuration panel. But generally everyone has converged on a standardized format for how these editors work. Which is great for users who don't have to relearn the patterns for every new app.

So now that we've seen a couple of examples of block-based interfaces, I want to give you a more concise definition of a “block”
I define it as a single unit of content...
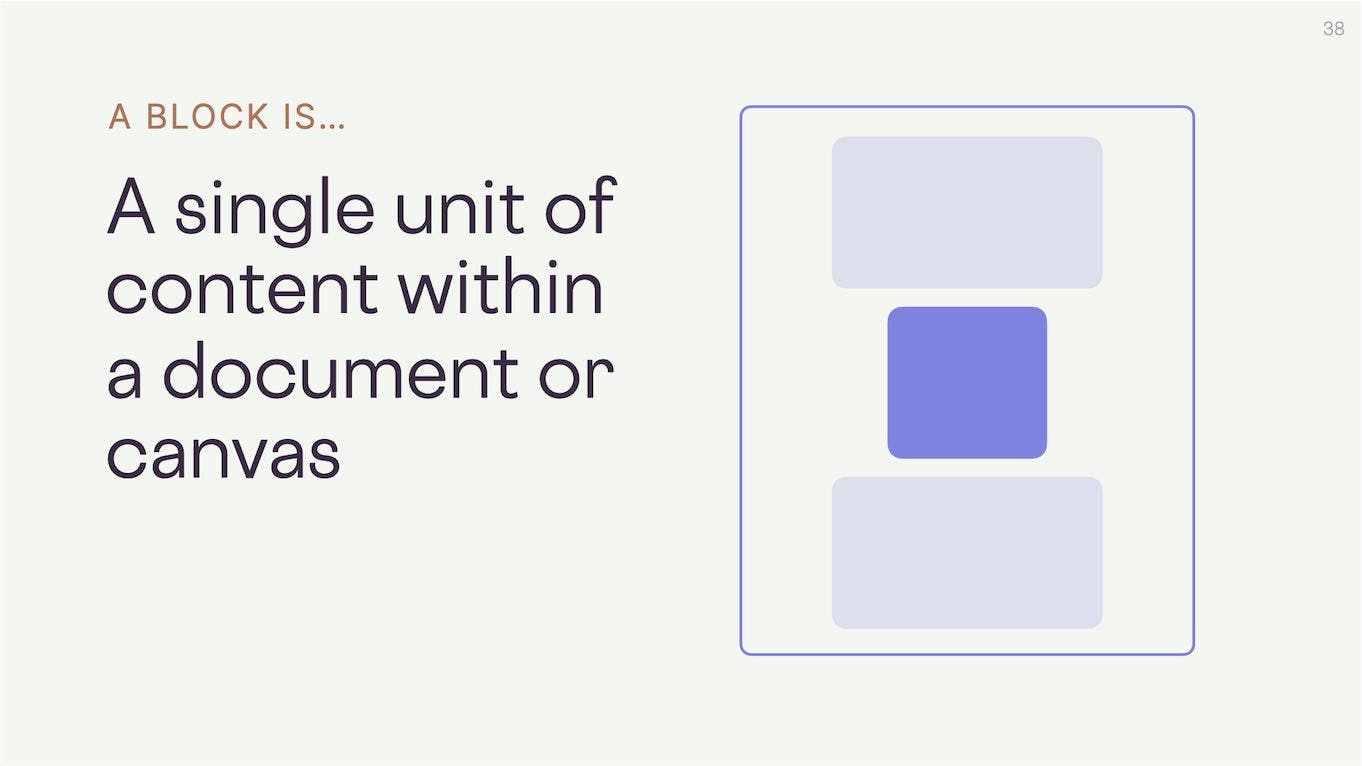
...within a document or canvas...

...that can be flexibly composed and rearranged...

...and has a type that determines how it displays data.
So a table obviously lays data out in rows and columns...

...while a kanban lays it out in a set of cards.
Another key feature of blocks is you can change that type while the data inside the block stays the same. This means we have a separation of the data from the view. So a set of kanban cards could become...

...an image gallery.

And critically, blocks allow end-users, meaning anyone who is not a professional developer, to create, edit, and delete the data within these blocks. All without writing any code. The users are in control of the data rather than the developers.
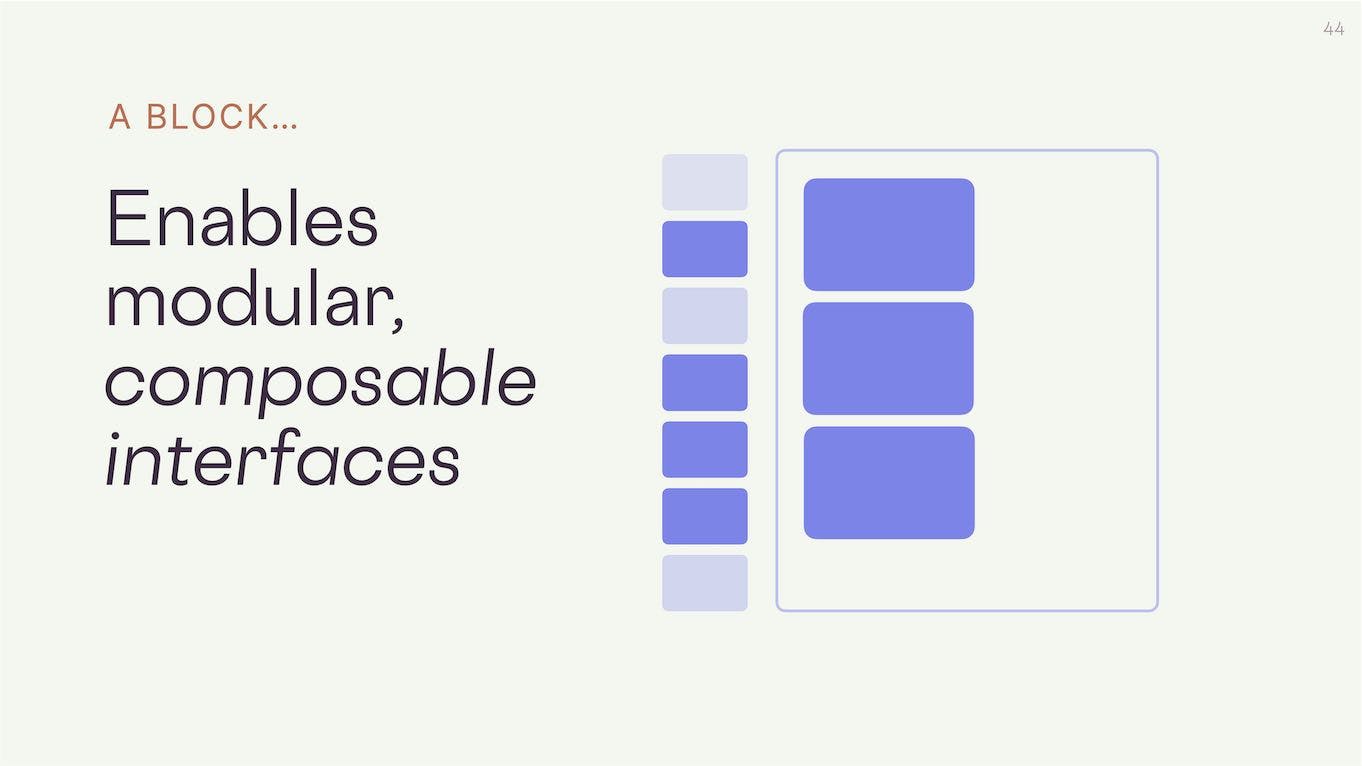
Blocks also enable what I call modular, composable interfaces. Open canvases where users can drag and drop blocks into place like legos. These are easy to use and accessible to a much wider audience than any markup or syntax could hope to be.

These types of interfaces are obviously very powerful and popular. And to explain why I'm going to reference a quote from Joel Spolsky, who co-founded HASH, as well as companies like Stack Overflow, Trello, and Glitch.
In his announcement post for Trello, he said "The great horizontal killer applications are actually just fancy data structures."
By "horizontal" he means applications that have a wide range of uses cases. Things like spreadsheets and word processors. Apps you can use for everything — from financial analysis to grocery shopping lists.
The reason these apps are great for such a broad range of use cases is they give users really strong data structures to work within.

And I think block-based apps are becoming the meta-medium for horizontal apps. They're a material with the potential to do whatever you need them to. They allow you to pick your own fancy data structures from a wide list.

Unsurprisingly, block-based apps have started popping up everywhere. There are three main categories they fall into.
The first is documents, wikis, and knowledge management systems. The kinds of apps people use for note-taking or team communications. This is the most popular use case at the moment.

The second is WYSIWYG website builders and web publishing platforms. This includes platforms like WordPress's Gutenberg editor, Squarespace, and Webflow. They're explicitly designed to help you create standard web designs like landing pages, contact forms, and blogs.
The third category that's just starting to take shape is what I'm calling “Do-it-Yourself SaaS tooling.” These apps give users the ability to create their own interfaces with a lot more programmatic functionality baked in. You can usually query a separate data source, add "if this, then that" logic to elements, and define more advanced block functionality like filterable lists and dropdown selectors.
Rather than subscribing to ten different SaaS services, these apps are beginning to let you build your own solutions.
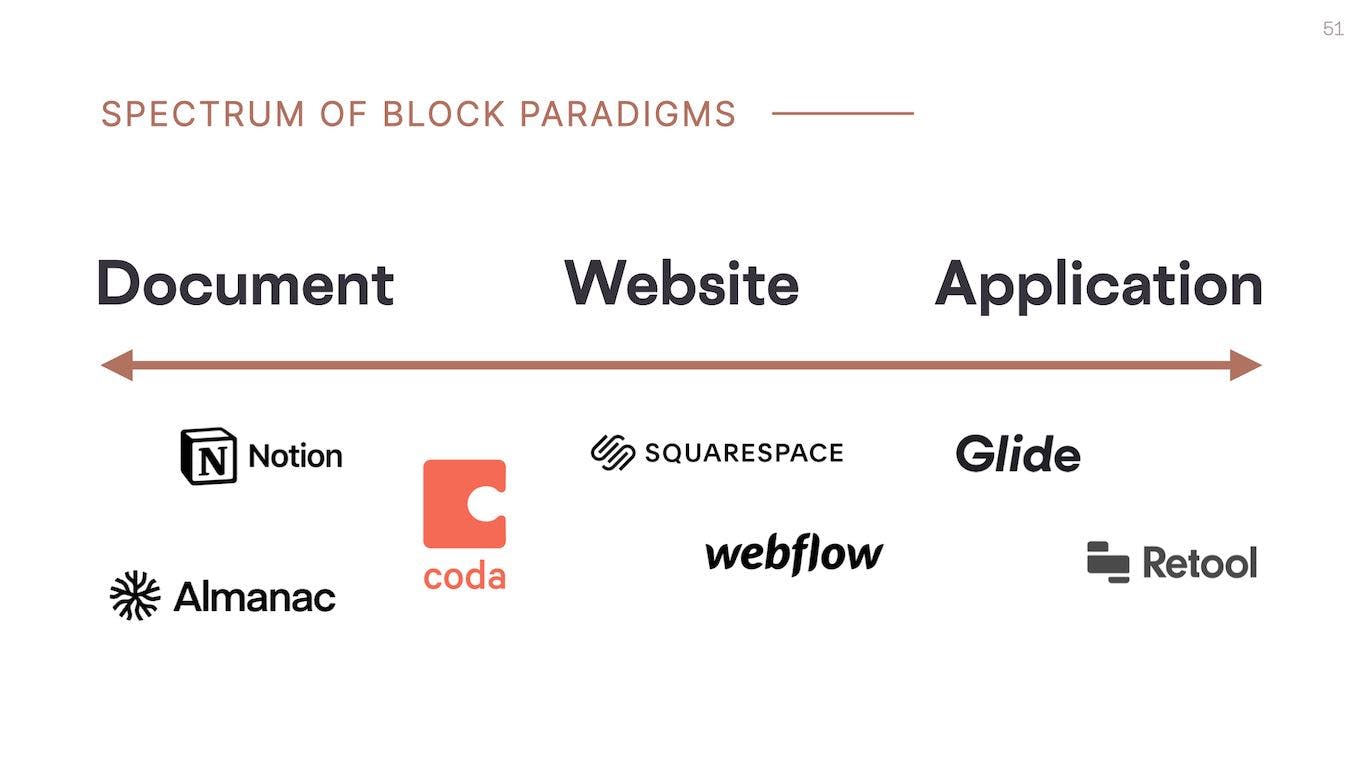
The lines between these categories are quite fuzzy. I think of it as a spectrum of block-based paradigms. Each app frames what you're creating slightly differently. Some present it as a document, some as a website, and some as a fully-fledged app.
But they're all following the same interface patterns to do it. The difference between these block-based editors become window dressing when you begin to look closely at what they actually make possible.
This is why so many people have ended up using tools like Notion as website builders, despite the fact that these tools were never built with the expectation of that happening.

But I think the real benefit of these block-based applications – the reason they're so widely used – is they shift power from developers to users.
They give users agency over what the app can do. Users are given a set of tools with enough flexibility to solve their own problems. Rather than developers, designers, and product managers imagining hypothetical problems for the user, and then imposing their ideas of how an app 'should' work to solve those problems.
Obviously, block-based interface do not fully hand over control to the user. But they enable more end-user programming to take place. And they're doing it in a way that was frankly impossible just 5 years ago.
If 5 years ago I wanted to put a table of data onto a website, I would be writing the HTML, CSS, and JS for that myself. And it would definitely not be as good as the table Coda or Notion give me. And now I can do it in two clicks.

We've established that blocks are wildly popular, and they enable hundreds of thousands of people to publish rich, complex documents to the web.
So, what's the problem here? And how does this relate to structured data?

First, blocks are proprietary to individual applications, and can't be moved between applications.
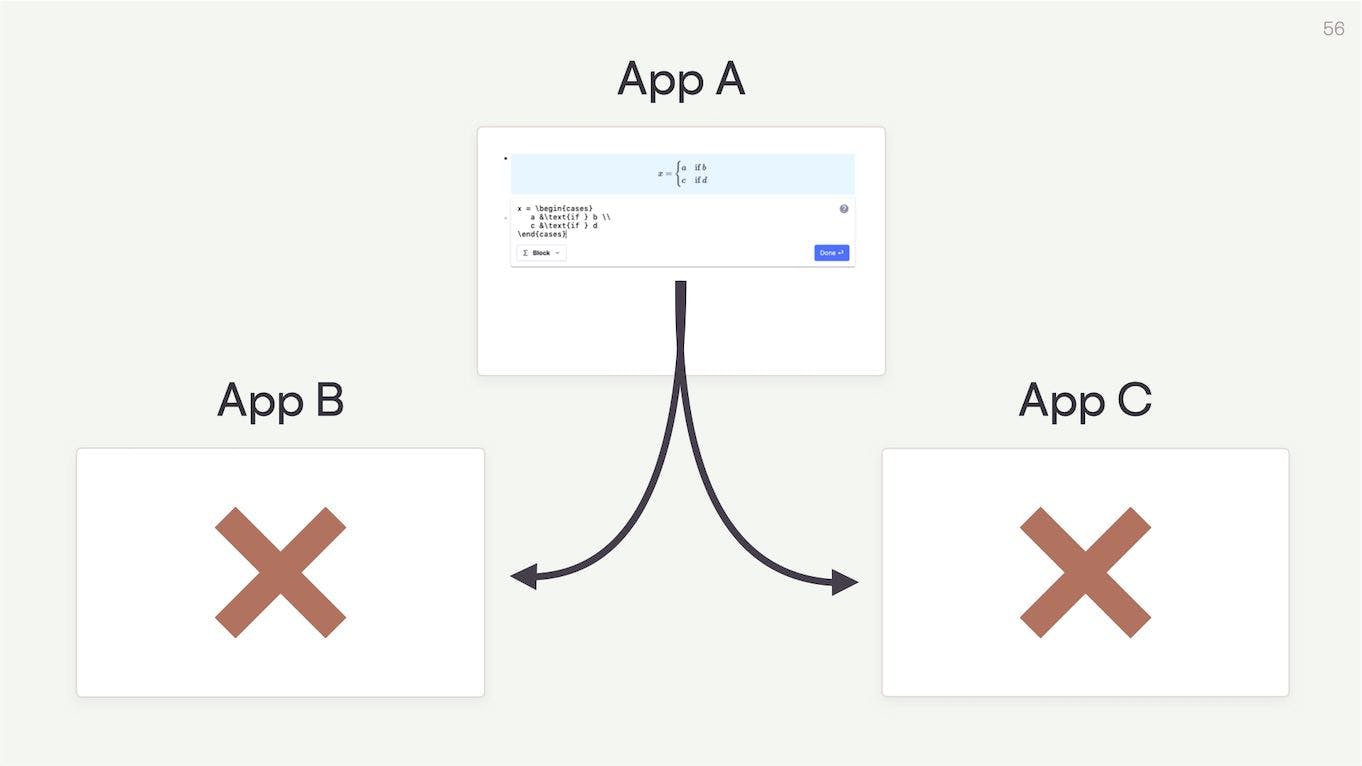
If I have a block that I love using in one of my apps – probably because it's well designed and easy to interact with – I'm only able to use it within that app.
Let's say there's a block that renders LaTeX beautifully in my note-taking app. But I also want to publish LaTeX code to my website and my company wiki. But those apps don't have blocks that render LaTeX. I'm now stuck. There's no way for me to port the LaTeX block across applications.

Closely related to that: an enormous number of developer hours are spent reinventing the same blocks over and over.
Most of these apps have the same basic types of blocks; header, checklist, table, image, embed, etc. But every team of developers has to build their own set of these.
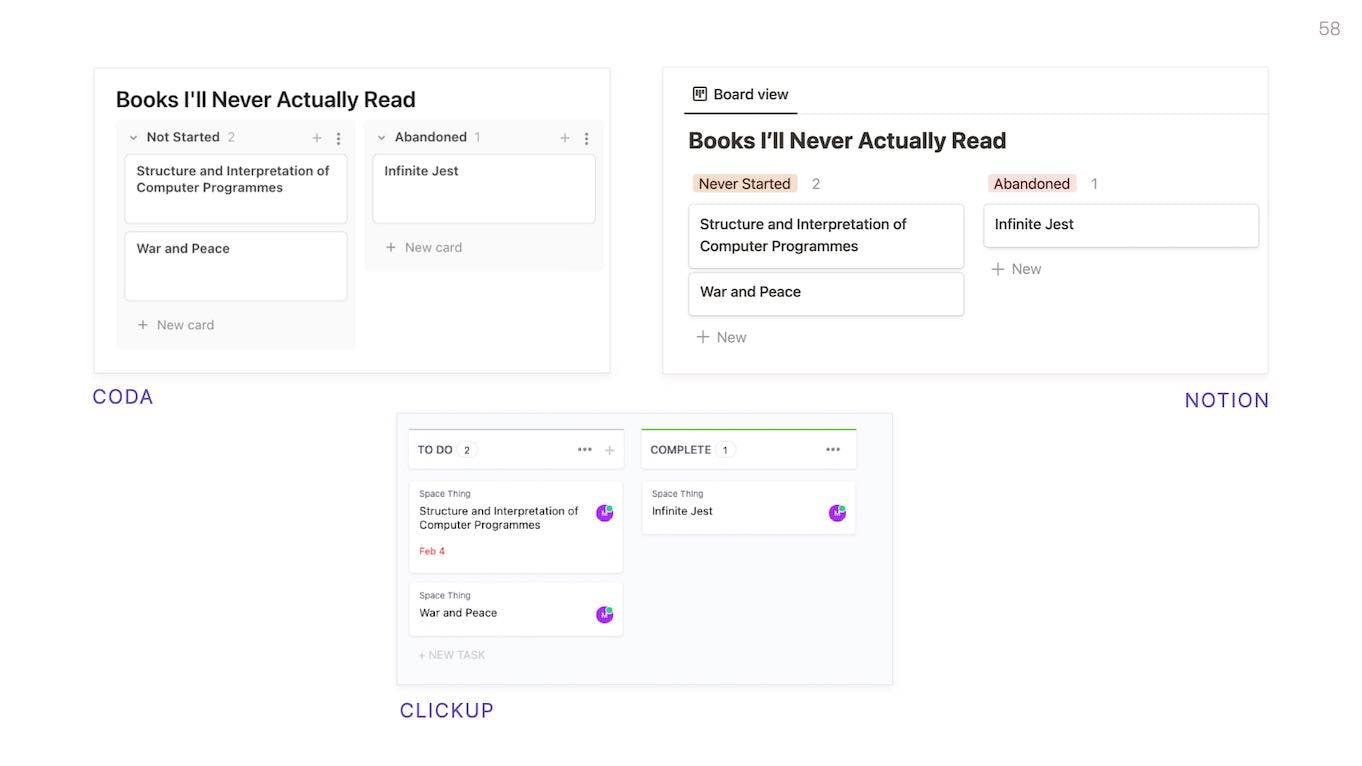
If we look at the kanban block in Notion, Coda, and ClickUp, we'll notice they all work the same. They offer the same basic functionality, format, and interactions. But the developers had to build each of these separately. (Editor's note: take for example apps like WordPress, DayOne and Tumblr — each of these from the single same company, Automattic, each using the exact same framework, Gutenberg, and yet each today has their own 'image' block, developed separately without shared abstractions to build upon)
Anyone building a new block-based app will have to build their own kanban board component for it, or heavily modify an existing one, even though this is a solved problem.
This is a waste of time and energy for developers. It's also frustrating for users, who have to learn slightly different interface patterns for each application. Even when their blocks all do the same thing in the end.

The next issue is that users only get access to a limited range of blocks.
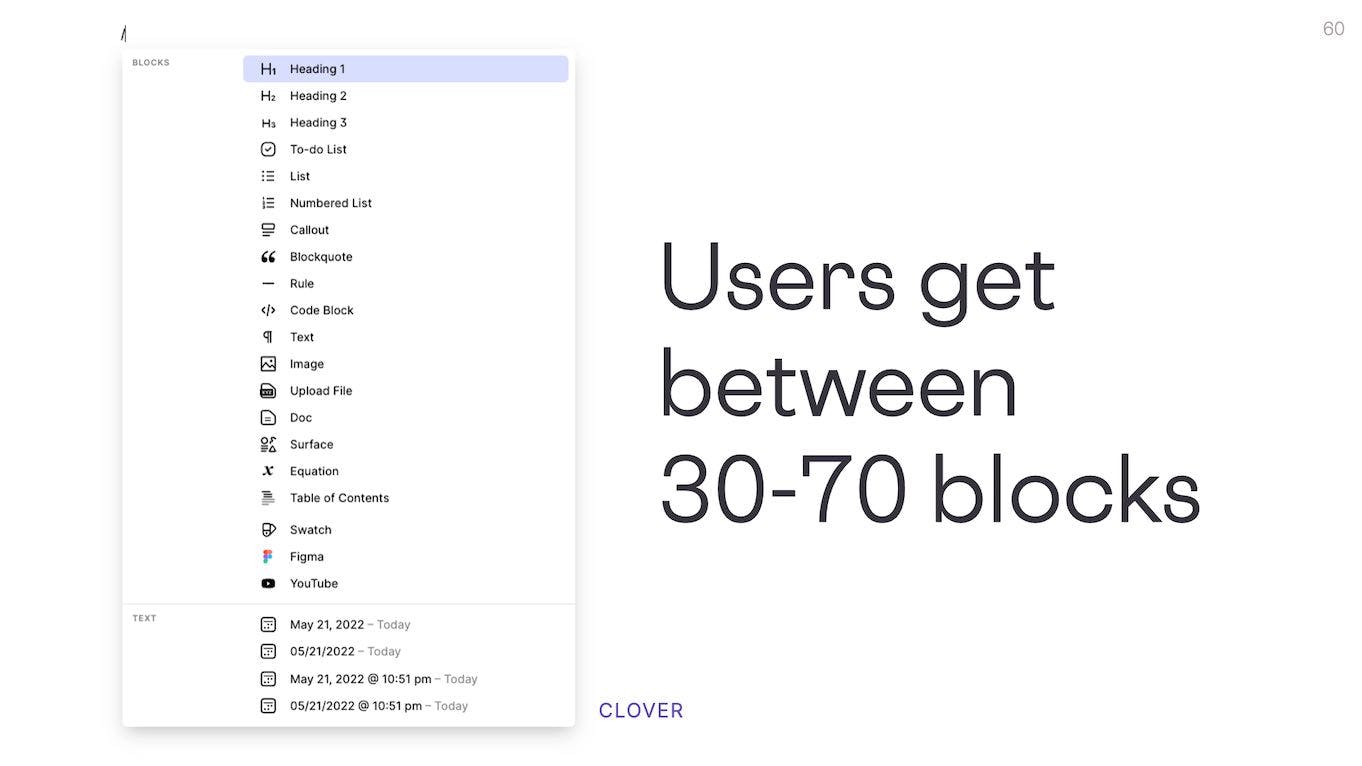
Users are given between 30-70 blocks in each of these applications, and usually on the lower end of that range.
Here's the block picker dropdown in an app Clover with a fairly typical list of options.
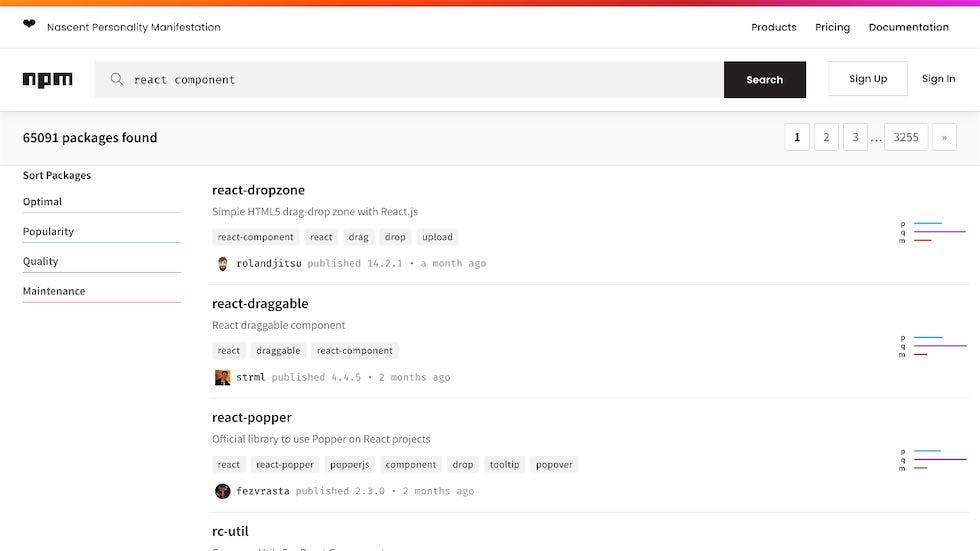
Compare this to what your everyday React developer has access to. If I hop onto the npm package manager for JavaScript, and search for “react components”, I get over 64,000 results to pick from. Obviously, not all of these components are going to be block-like things. Many will be utilities or helpers.
But this still shows there is a huge discrepancy between the power and choice developers have when constructing an interface compared to users.

The final and biggest problem with proprietary blocks is that there's no structured data behind these blocks, which in turn leads to poor data interoperability between platforms.

A table in WordPress Gutenberg and a table in Notion appear to have the same data structure on the surface. They both have values stored in rows and columns. But they're built differently on the back-end. They're not designed to be shareable. This means we can't easily pass data from a Gutenberg table into a Notion table.

Which brings me to our last section: the Block Protocol!
The Block Protocol is a project by HASH that hopes to address some of these problems.
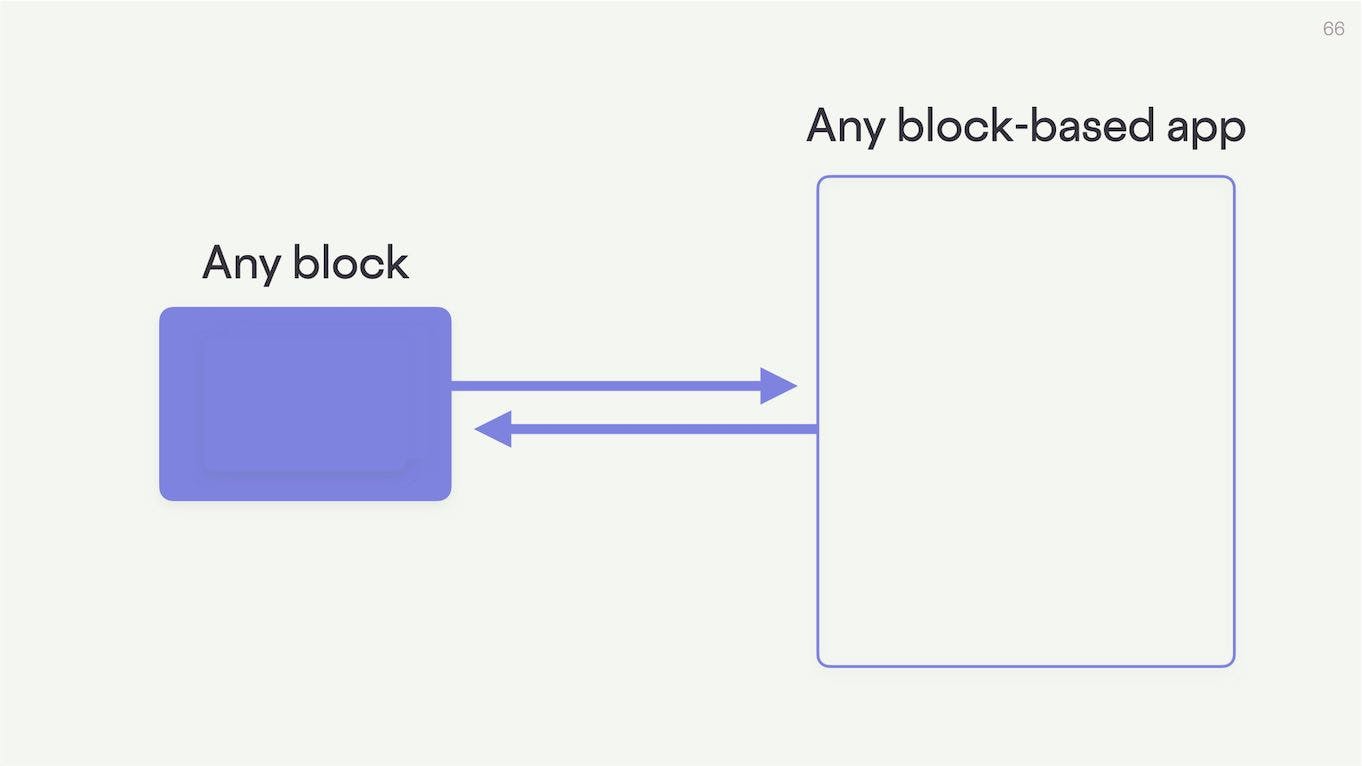
It specifies a standardized way for any block to communicate with any block-based application.
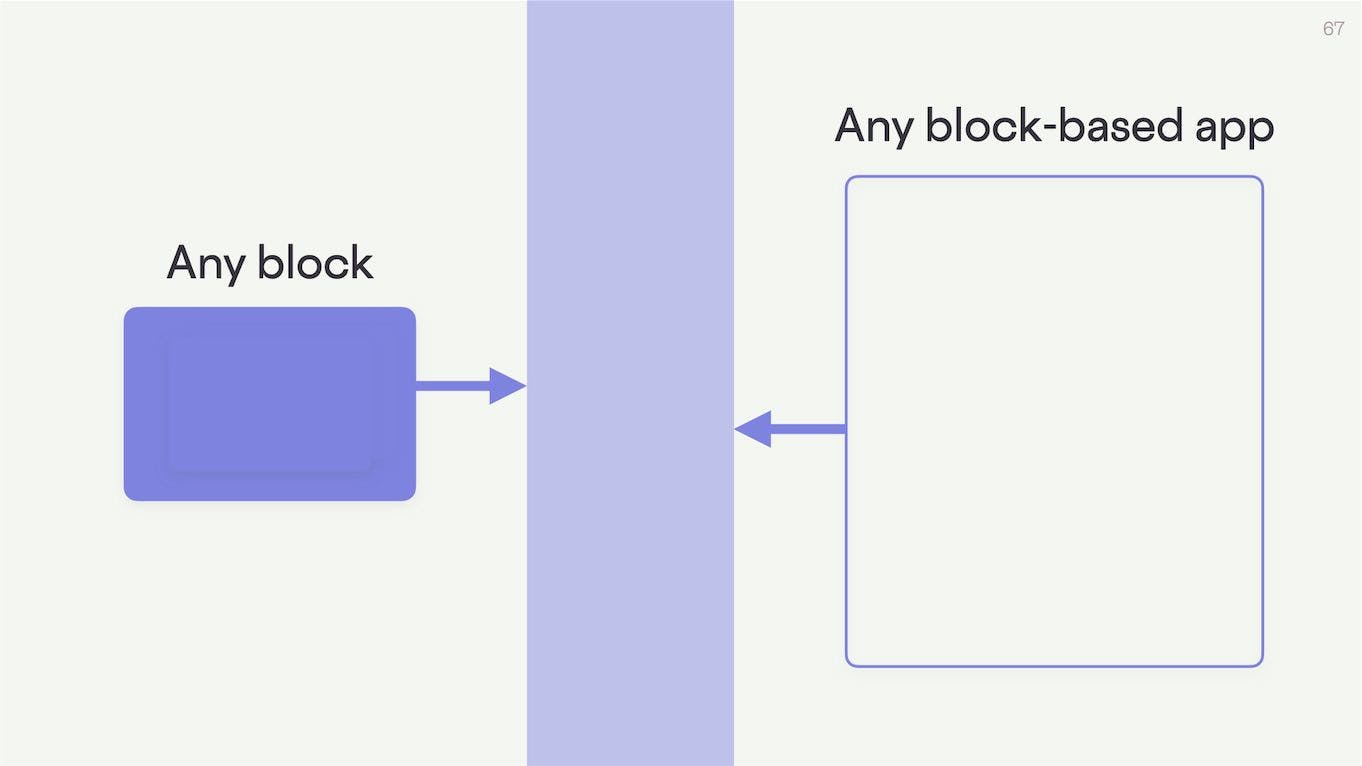
But rather than these two systems talking directly to one another as they like, they instead both communicate in a way defined by the protocol. The protocol in essence provides a shared set of terms for negotiation between the two parties. A bit like a set of rules about what you can say and how you should say it.
Any block that talks to this protocol can talk to any application that also speaks to it, and vice versa.
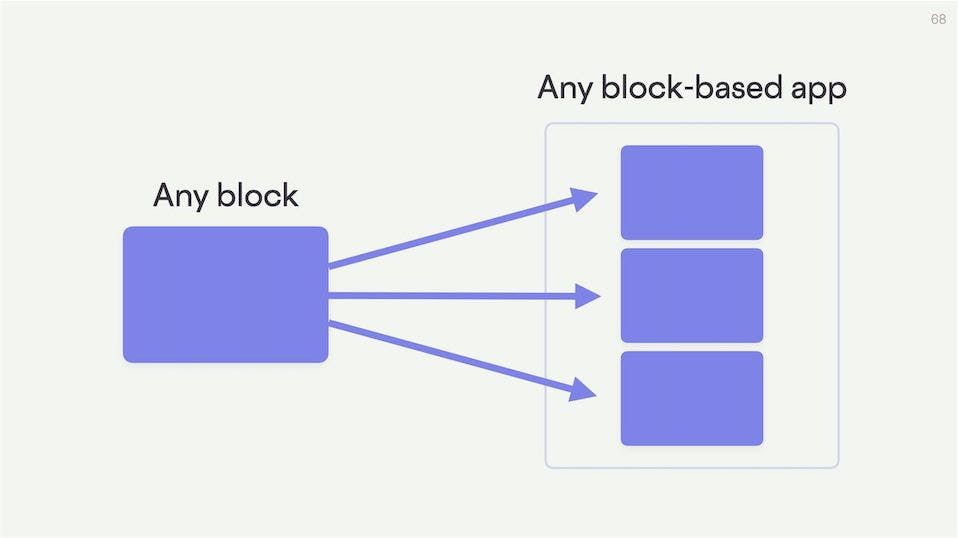
This makes it possible to embed blocks that follow the protocol into any app that also follows the protocol.
The developers of the block and the application don't have to know anything about one another, or co-ordinate their efforts. But they can make their software compatible through the protocol.
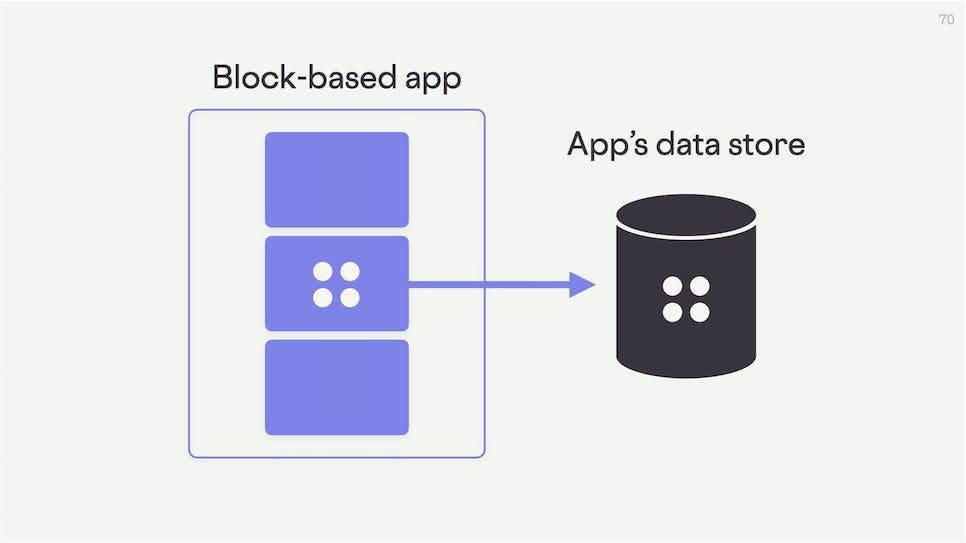
Embedding is great, but what we really want here is data exchange.
Our app has a data store that it controls. And our block wants to create new data. Let's say we've made a table block and typed some information into it.
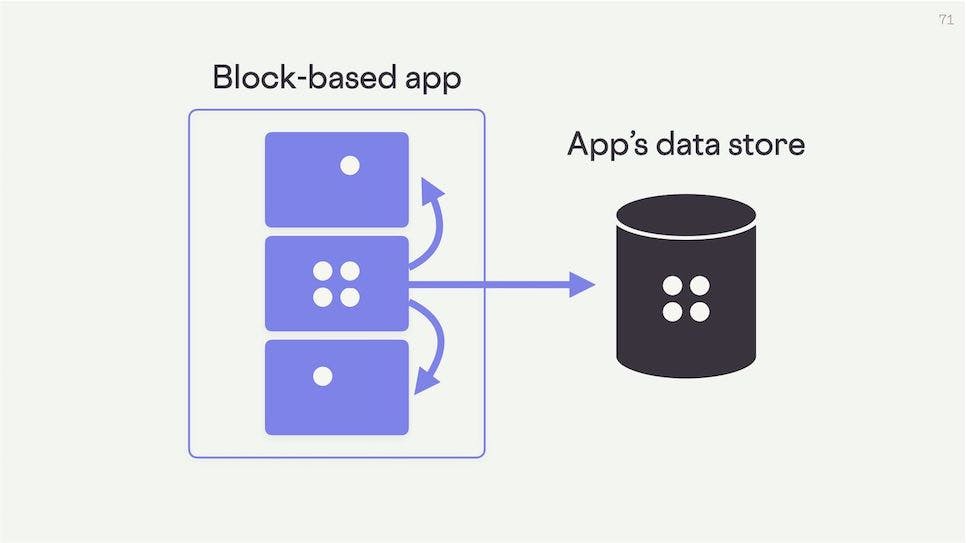
Using the protocol, our block can send that data to the app's data store. It can then do all the standard operations you would expect. It can create new data, update existing data, delete data, and read data from the app.
Obviously, the block can only make these changes with the permission of the app. There are certainly security implications here we're anticipating and building accommodations for.

Well, so what?
Why do we care that all this embedding, data exchange, and interactivity is possible?
First of all, it means that any independent developer can build a block. Then anyone else can put that block into their application. And it'll work without requiring extra dev work. As long as they both use the protocol.

But really, so what? What does this mean in terms of practical user benefits?
Well, in this hopeful world, users would be able to pick from a much wider variety of blocks.
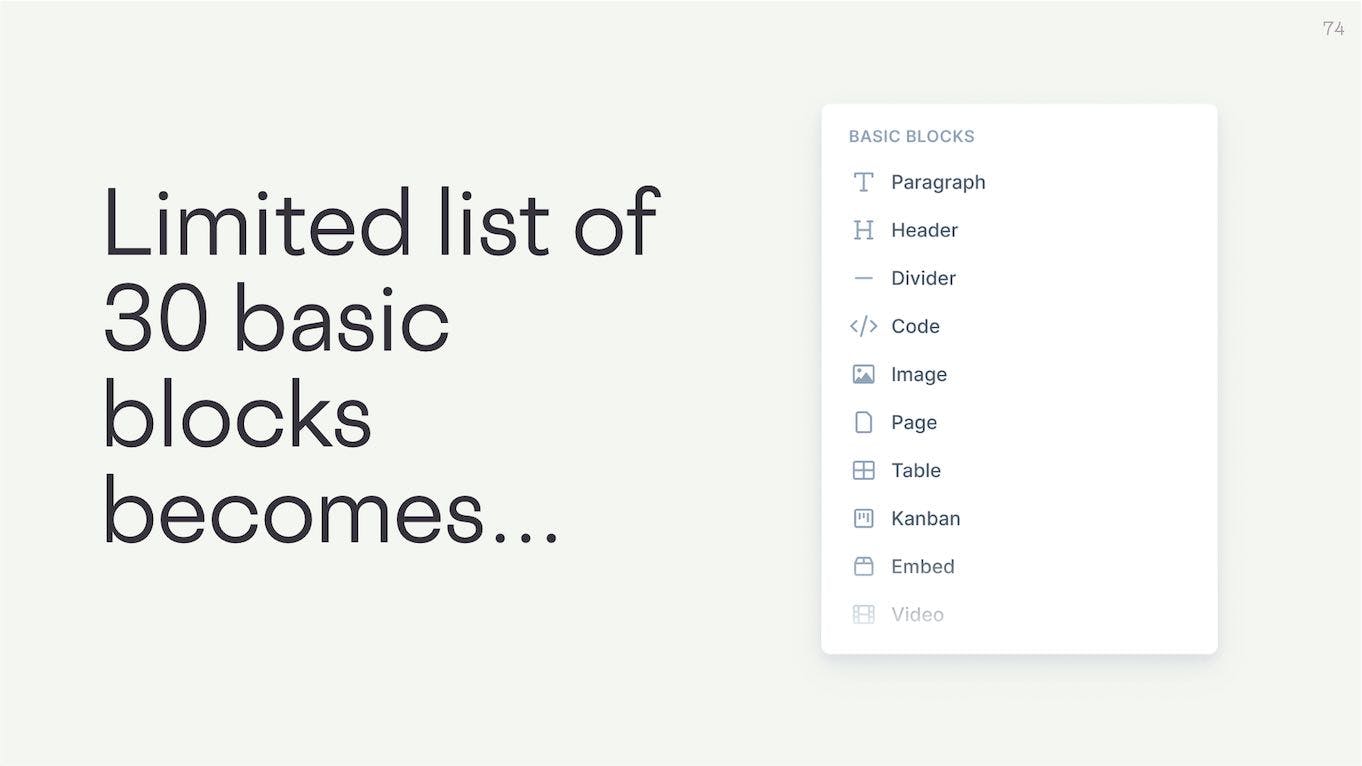
At the moment users get this limited list of 30 or so basic blocks.
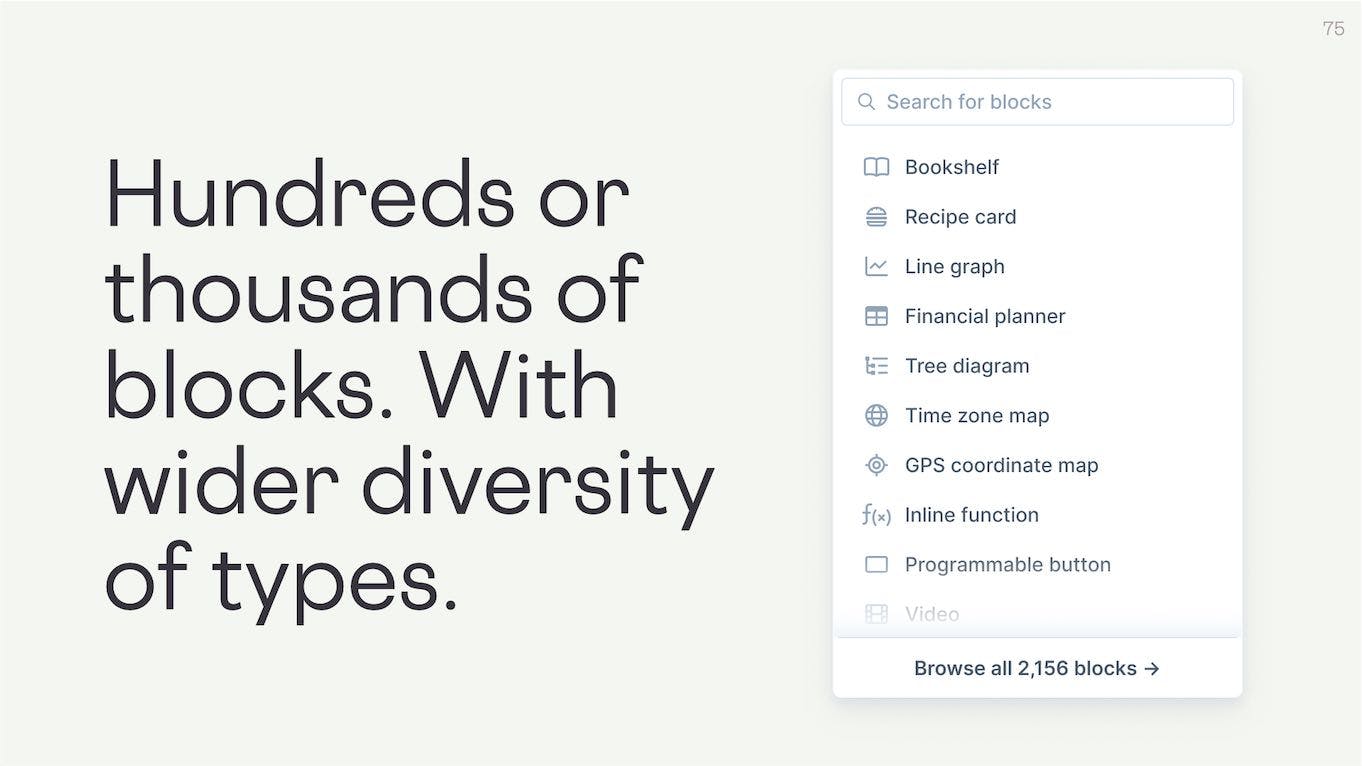
But we would love to make it possible for users to have hundreds or thousands of specialized blocks to pick from. They should have a much wider variety of types available in their apps. People should be able to pick from weirder, niche blocks like recipe creators, data visualisation displays, flight path trackers, or financial planners.

Secondly, applications would get access to this wider range of blocks for little or no extra developer work.
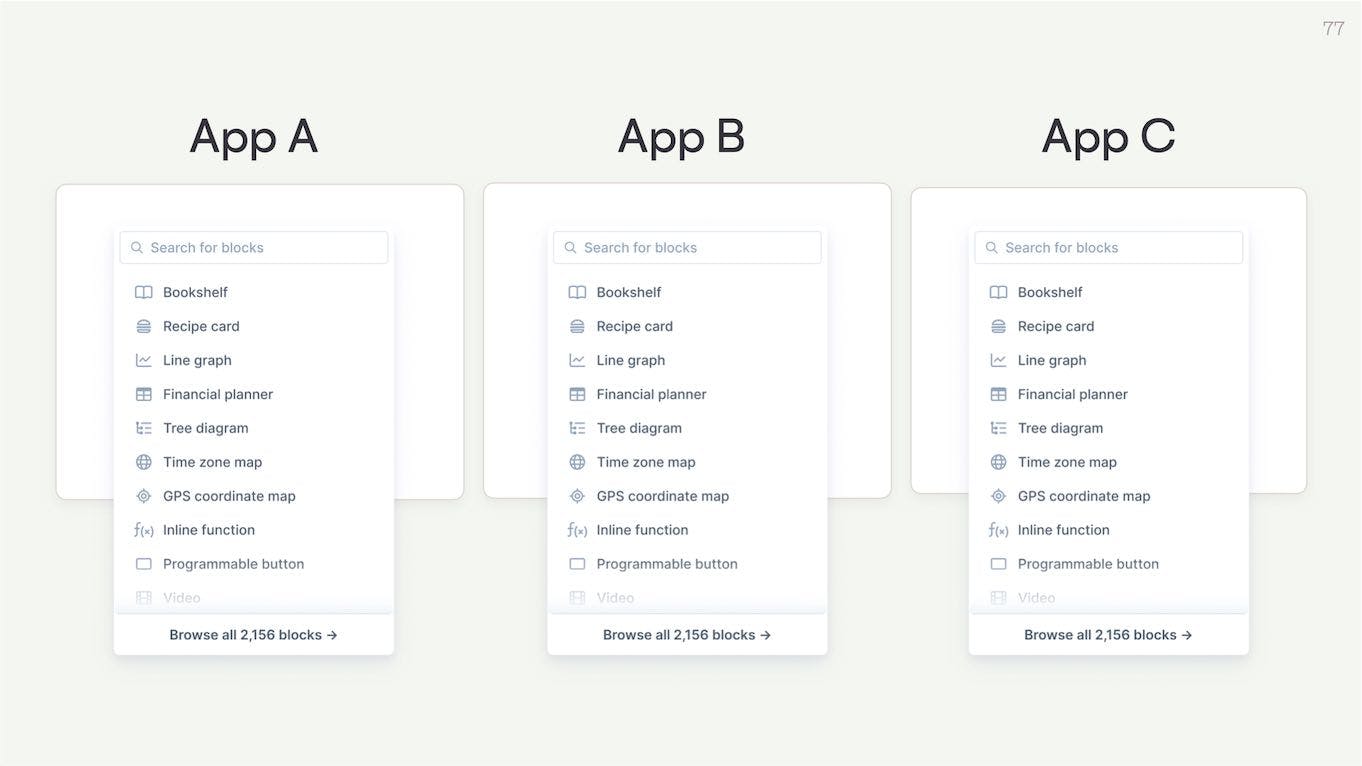
Each app would be able to make this infinite list of block options available. Which saves the developers building those apps from having to make all these block types themselves, or rebuild a table block for the 100th time.
It also offers their end-users a much better experience. Which is the whole point of their company.

Lastly, this protocol makes it easier to create structured data and encourages more data interopability.
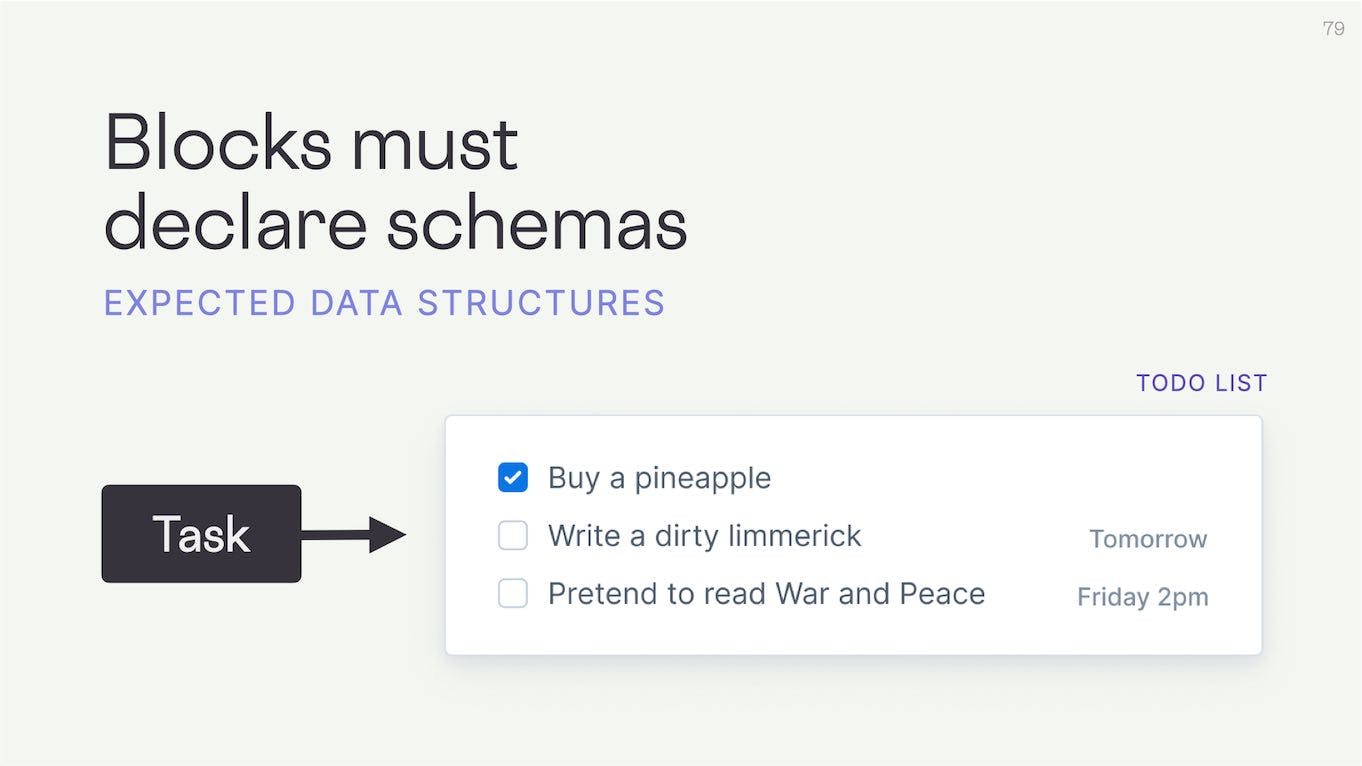
Blocks that follow the protocol must declare a schema – an expected data structure.
So a to-do list block would expect to receive a set of Task items.

And that Task will have an expected list of properties like a title, description, status, and dueDate. We declare these in a JSON object and validate them with JSON schema.
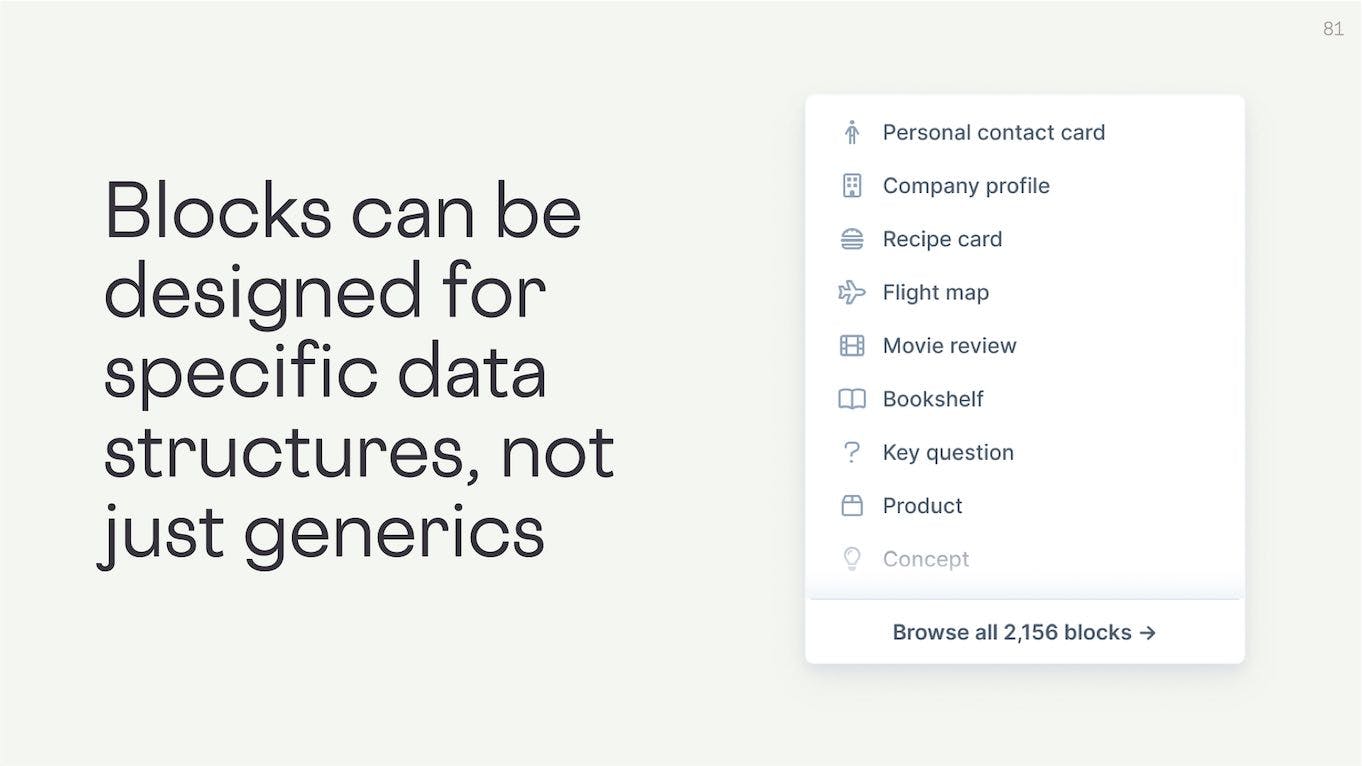
This means that blocks can be designed to fit specific data structures, rather than all being generic formats.
We could have very specialized block types like a Flight Map block that takes in a Flight data structure, or a Movie Review block that takes in a Movie data structure.
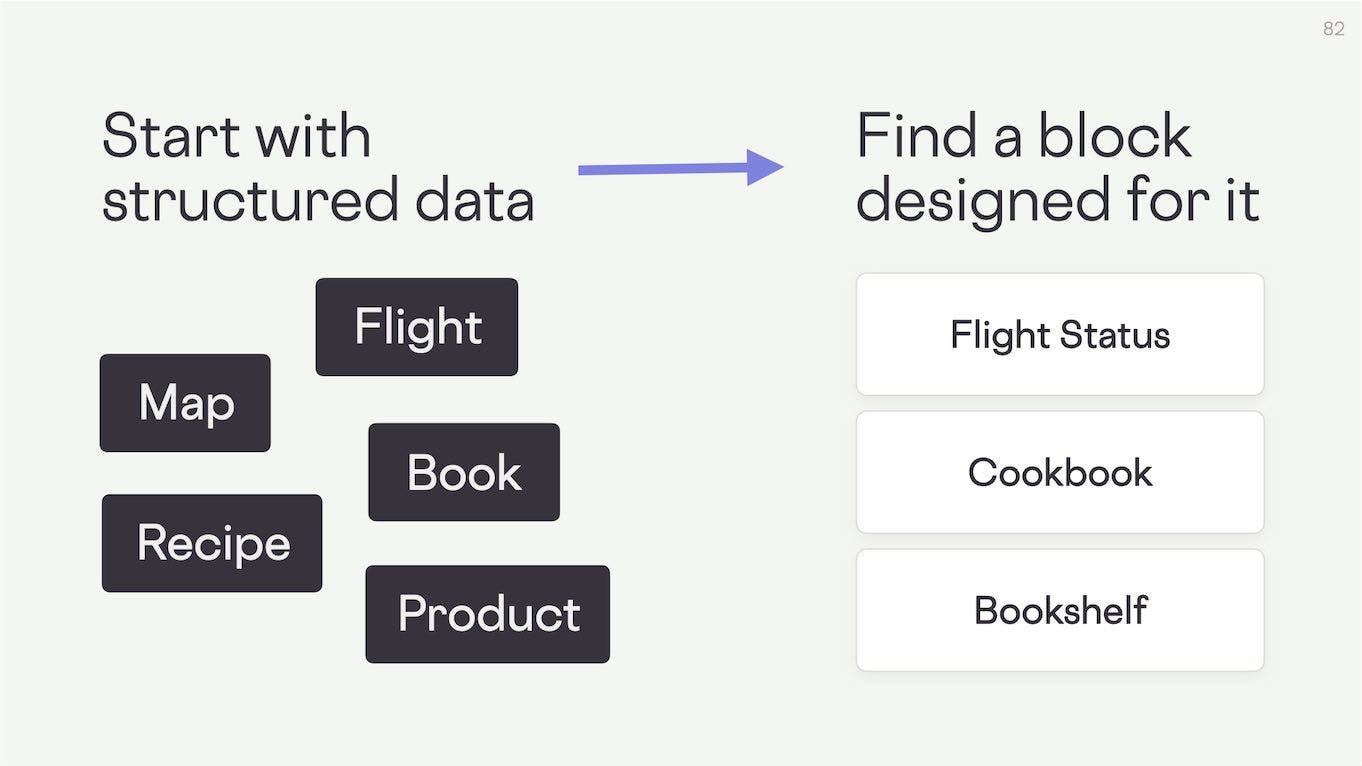
This gives us an interesting new interplay of data and views. We can start with structured data – with specific concepts – and then find a block that's specifically designed to display it.

The power of this can best be explained by a quote from the late, great Christopher Alexander: “Design is finding a form to fit a context”
Structured data is a kind of context, and blocks give us the flexibility to find the right form for it.

There's also another layer to this. We can go the other direction and use blocks to create structured data.
We can start with a block which has a user-friendly interface to input and edit data. And once we've typed values into it, the block can create the structured data for us, because it already has a schema defined. And this is all a much better user experience than writing JSON-LD or RDF code syntax.

So this is all a lovely idea, but I'm sure many of you are already thinking of all the horrendous ways this could go wrong.
There are plenty of challenges and problems with trying to build this protocol, and we're actively working on them in public. The current specification of the protocol is an early alpha draft that we're looking for feedback on.
A few of the major challenges we have draft solutions for are security and sandboxing for untrusted blocks, maintaining consistent UX and styling across blocks, and handling schema divergence.

There's many more of these. We have an FAQ page with extensive answers written for each of these. We're always looking to add more so feel free to get in touch if your question isn't answered.
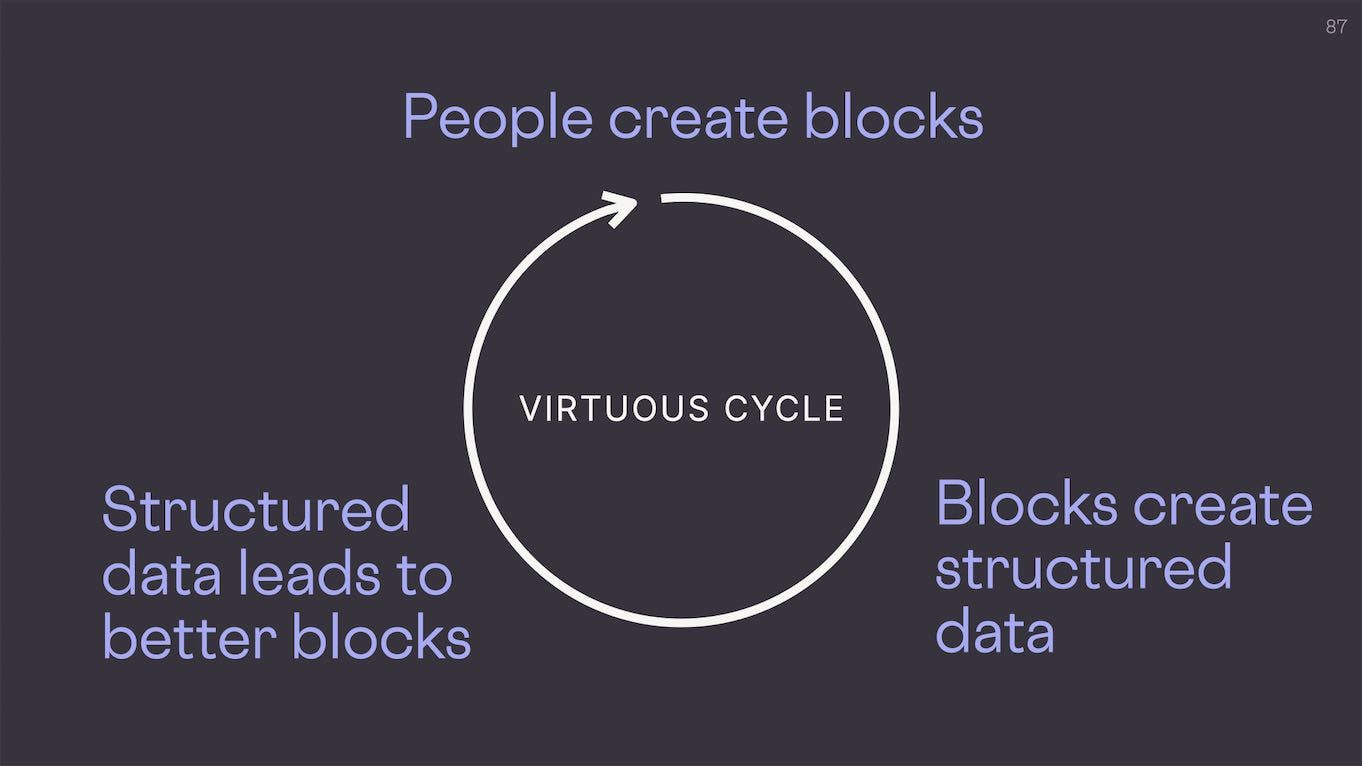
The bigger picture goal of this whole project is to create a virtuous cycle. We want people to create blocks, so that blocks can create structured data, so that people have access to more structured data to reuse in blocks.
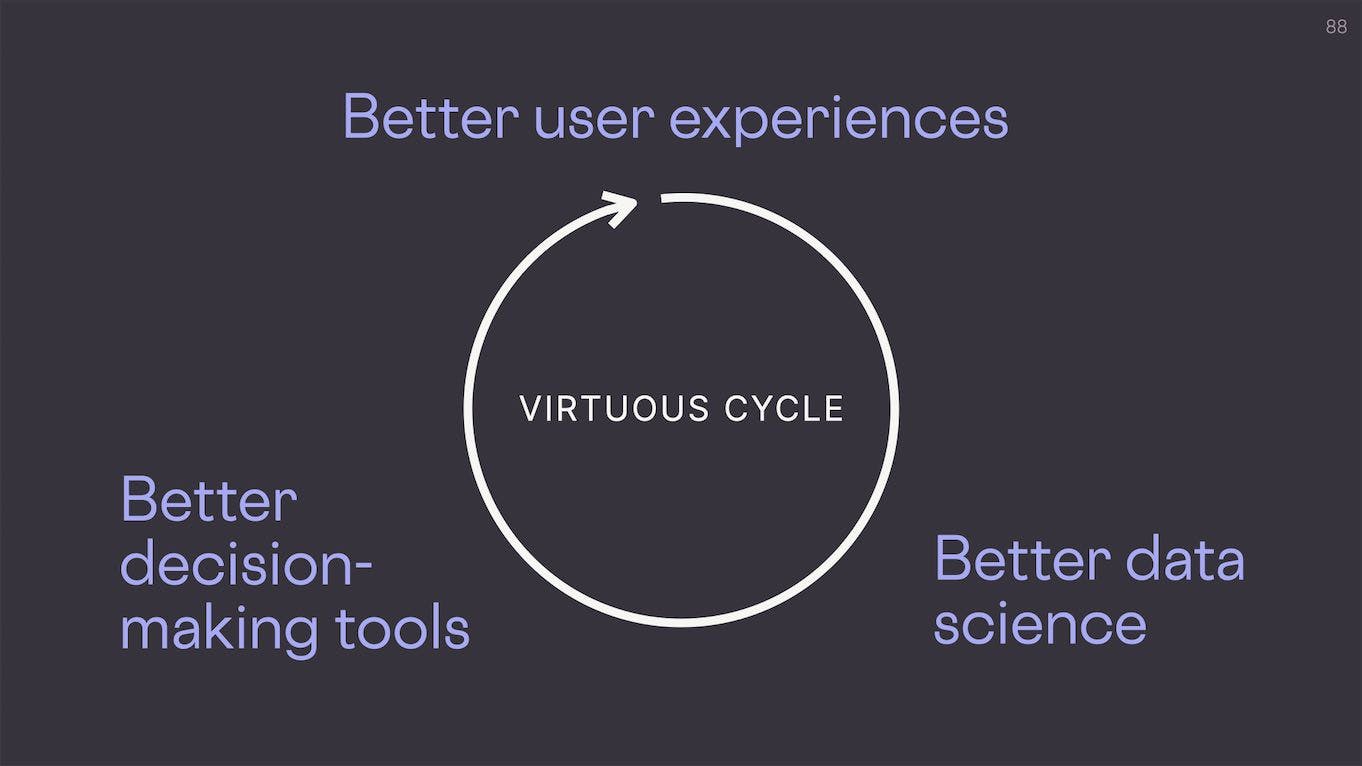
In turn, we hope this leads to better user experiences, better data science, and eventually better decision-making tools, like HASH. Thank you!
Get new posts in your inbox
Get notified when new long-reads and articles go live. Follow along as we dive deep into new tech, and share our experiences. No sales stuff.