File structuring using fractal trees
Scalable code organizing for large projects and monorepos
August 30th, 2023



This post is the first in a series from HASH on minimizing entropy in large, actively growing codebases. It outlines an approach we use when structuring JavaScript source files, which employs the concept of fractal trees. The solutions can be applied to parts of a codebase, as well as projects as a whole, allowing for incremental adoption.
Context
At HASH, we maintain a large public monorepo, hash. In the context of this monorepo, this post's scope is limited to the internals of Yarn workspaces, while the locations of the workspaces themselves are out of scope. In a future post, we'll discuss competing approaches to structuring projects within multi-language monorepos and our recommendations here, explaining why our primary monorepo looks the way it does.
Problem
Managing source code gets harder as codebases grow, the number of contributors increases, and time passes. When dealing with hundreds, thousands, or more files, it becomes difficult to decide where to write new code because things start to look messy. Commonly observed folders like components, models or utils generally end up collecting large quantities of unrelated code, some of which become obsolete, but may not be cleaned up. It is not always easy to evaluate the possible side effects of a change because colocated files can have radically different impacts on the rest of the codebase.
JavaScript is used in a broad range of software products. Structuring backend, frontend or library code is often approached on the case-by-case basis, thus turning new projects (including new monorepo workspaces) into bespoke craftwork. For the codebase to grow, collaborators may need to learn different folder layouts and agree on more or less unique rules in each case.
While some file structure is established in the early days of a project, it may erode over time and become obsolete. However, fixing this structure may be costly. Refactoring work not only takes time, but may be subject to debate, planning, testing, and requires stakeholder education.
Solution
Our solution is to adopt a universal approach to source file structuring, based on the principles underlying fractal trees.
A new project is initiated with just one root source file and is then grown organically by following a small set of basic rules.
Project complexity is distributed across the whole tree, which makes the resulting structure robust, flexible, self-explanatory and highly scalable.

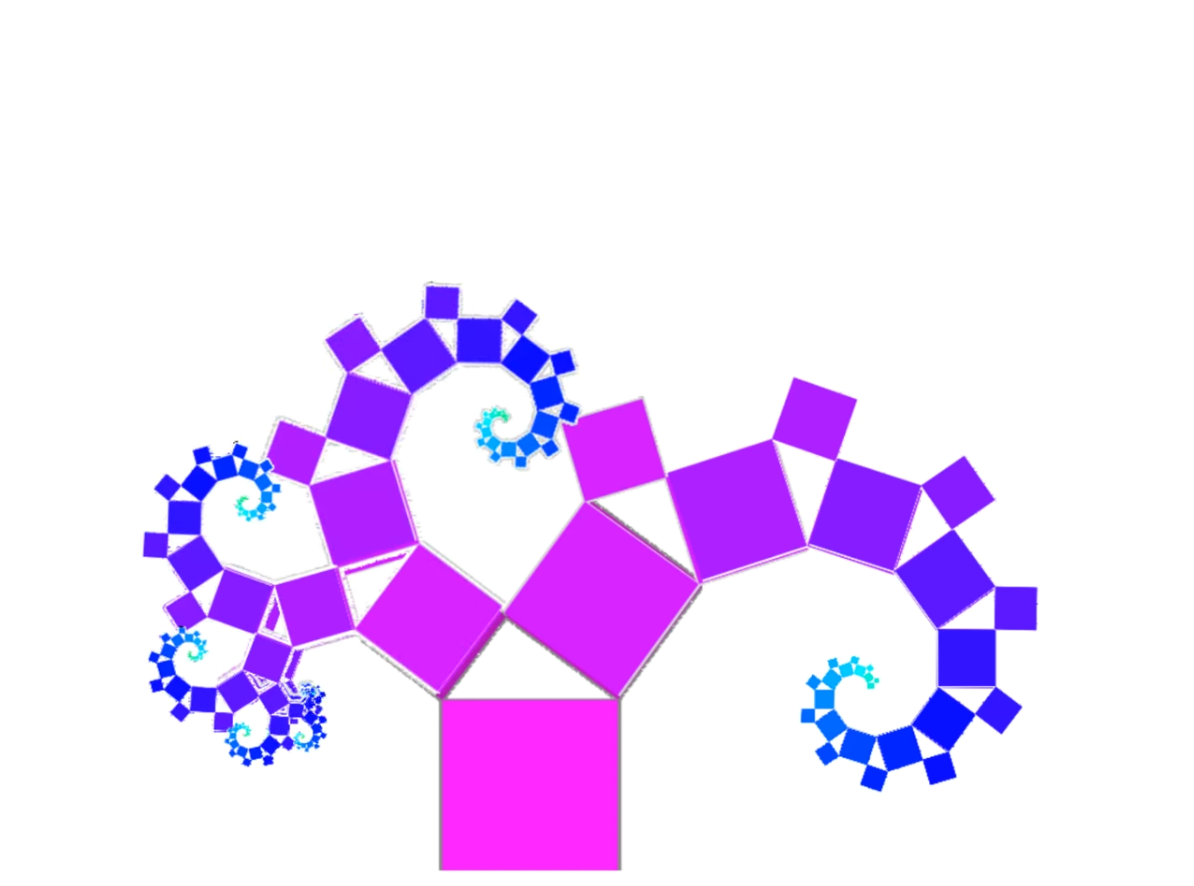

Our approach builds on the destiny npm package and Prettier for file structures talk from Ben Awad. The fractal tree approach to file structuring is underpinned by 6 principles. These in turn inform our rules.
Principles
P1. The structure of the whole project is the same as of any of its parts
No matter what part of the project we open, we want to find familiar patterns and thus confidently make changes to what we see. A developer should not need to learn the entire project structure in order to be able to contribute to its part. Broadly speaking, the codebase can successfully evolve even if there is no single developer who has painted a detailed picture of all source files and folders.
P2. Circular dependencies between files are disallowed
Creating circular import chains would turn the fractal tree into a more generic graph structure. This would increase the complexity of the rules to follow and could also introduce runtime bugs.
P3. File trees grow organically
🌱 → 🌳
There is no boilerplate file structure. A single-file project is still a fractal tree, just as a project consisting of tens of thousands of files. In theory, a tree of any size can be packed into one file, although doing so in practice would make this file very difficult to maintain.
Resources are grouped into files by their functional purpose rather than ‘shape’. This means that we don’t have project-wide folders like components, hooks, services or types as this would be similar to putting all CSS or HTML files next to each other. Instead, we name and distribute the files based on their added value. The resources that comprise a ‘feature’ (components, hooks, services, types, etc.) may remain an implementation detail of a sub-tree and do not need to be exposed outside this sub-tree.
P4. Resources of a sub-sub-tree are inaccessible
Each sub-tree exports resources which can be imported on the next level of the tree. Direct imports from a sub-sub-tree is not allowed because these resources are considered ‘private’, unless re-exported. As a result, internal modifications in a sub-tree cannot cause unexpected side-effects to the rest of the codebase.
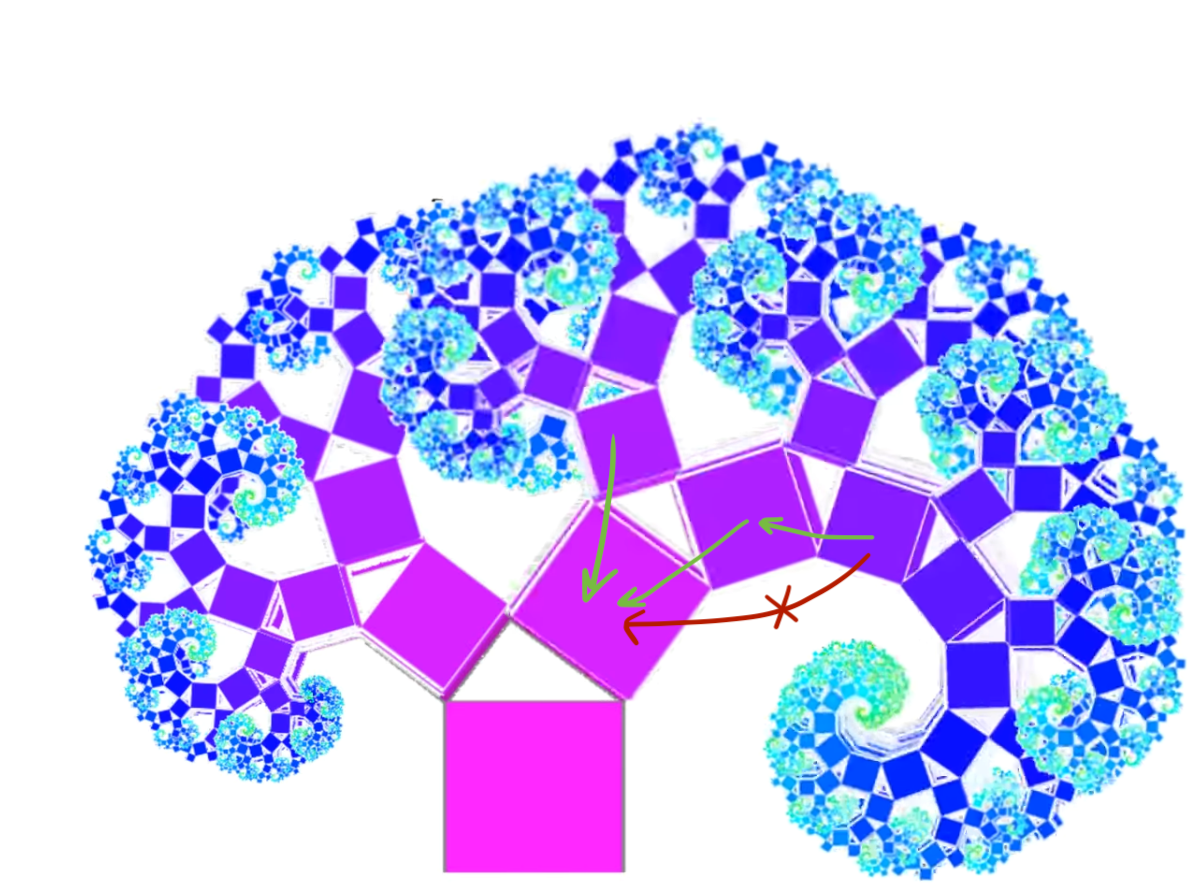
P5. Shared resources may be introduced in any part in the tree
If branches of a fractal tree need to share logic (such as helper functions, constants, etc.), a shared resource is placed at the closest available ‘fork’ in the tree. If the scope of the shared resource has changed over time, a file is moved accordingly. Each ‘fork’ in the tree can accommodate multiple shared resources. Each of the shared resources is a root of a fractal sub-tree by itself.


P6. File structure matches the current state of the project
We do not need to think about file future-proofing. It is enough to ensure that the current state of the file tree represents the current state of the logic tree. Moving files is cheap and we should not worry about occasional tree reshuffling. The structure is designed for change.
By excluding future-proofing from the process, we save time on costly debates and also avoid over-engineering. We also allow ourselves to add formal linting checks to continuously verify file structure integrity.
Rules
The rules are informed by the above principles, which establish the general thinking framework. The rules, in turn, provide practical guidance to developers to ensure coherent and smooth DX.
Examples below mention .js extension for simplicity, but they apply to
TypeScript and JSX files too.
Rule 1: All file and folder names are in kebab-case
Avoiding capital letters saves us from crashes on case-sensitive file systems. For example, import "./Foo.js" may not work on Linux if a file is named foo.js. And unlike camelCase and PascalCase, kebab-case also maps well into URLs and npm package names. We use unicorn/filename-case to maintain consistency in file names.
Rule 2: No index.js files
These ‘special’ files enable imports from folders in Node.js. For example, require("./foo") resolves ./foo to ./foo/index.js if the index file is present. However, this resolution mechanism does not work in ESM imports, i.e. native web and platforms like Deno (see their docs). The creator of Node.js concedes that although cute, index.js files needlessly complicate things (watch ‘10 Things I Regret About Node.js‘). By refraining from both using index.js and implicit folder imports, we improve codebase compatibility with different runtimes. We also protect ourselves from confusing path synonyms like "./foo" mapping to both "./foo.js" or "./foo/index.js". The entry point to an npm package can be named main.js instead of index.js.
Rule 3: Each file is a ‘mini-library’
A file in a fractal tree can expose one or more named exports, all of which should serve a common semantic purpose. The name of the file summarises its contents, e.g. maths.ts presumably contains various maths functions and symbols. If a file contains only one export, it is recommended to name it after that export, e.g. import { doSomethingCool } from "./do-something-cool.js", as doing so simplifies search.
When reasoning about the boundaries of a file, it is helpful to imagine this ‘mini-library’ published on npm. If it is hard to come up with a good description for a new hypothetical package, the boundaries of the file are probably ill-defined. It may be the case of unrelated resources being unreasonably mixed up (e.g. utils.js with some filesystem helpers and React hooks).
We avoid default exports unless it is an external requirement.
Rule 4: Outgrown files are converted into sub-trees of files
Because each file is a ‘mini-library’ on the conceptual level, all of its logic, except external imports, can be defined in one place. However, this runs the risk of certain files becoming too crowded, necessitating distribution of a ‘mini-library’ on the disk.
When any part of a ‘mini-library’ is extracted, the new files should be placed into a folder named after the original file name. For example, if we extract helpers named bar and baz from path/to/foo.js, new files are created at path/to/foo/bar.js and path/to/foo/baz.js. New file locations communicate their relationship with path/to/foo.js which becomes the root of a newly created sub-tree. Only path/to/foo.js is allowed to import from path/to/foo/*.js because this folder is considered ‘private’ from elsewhere. If path/to/foo.js is no longer used, it can be safely deleted together with its ‘private’ path/to/foo/ folder.
If any of the ‘mini-libraries’ in a sub-tree needs further splitting, the process of new file extraction repeats. Essentially, path/to/foo.js can only import files from path/to/foo/*.js and not from path/to/foo/bar/*.js. This is because path/to/foo/bar/ is a ‘private’ folder which is only accessible from path/to/foo/bar.js.
There is no hard recommendation on when to split a file because situations are different. For example, a file with a complex React component can benefit from extracting a few helper components and placing them in a subfolder (i.e. sub-tree). However, there is no need to do this from the start if the original file in its current form has no maintenance issues. Splitting makes sense only when issues become real, not hypothetical. Premature file splitting makes the folder tree larger than it could be, which is a sign of over-engineering.
For the consumer of a ‘mini-library’, no difference exists between its being a large sub-tree with thousands of files, as opposed to a single library. Internal sub-tree restructuring does not affect the exposed resources.
Rule 5: All imports within a workspace use relative paths
Importing something from another workspace is as straightforward as package-name/optional/path/to/something.
But when faced with the need to import from the same workspace, we have two options:
- use relative paths, e.g.
../../../foo/bar - create top-level aliases for some folders, e.g.
@/fooformy-workspace/src/foo. Next.js supports this style; other types of workspaces can be configured to support it too.
The problem with the second approach is that it creates two correct ways of doing the same thing. If we are in my-workspace/x/y.ts and we want to import from my-workspace/a/b.ts, we can either write ../a/b or @/a/b. Using @/a/b requires additional setup, which can become a source of tooling incompatibility, team debate, and other wastage of time. It is easier to always use relative paths.
Rule 6: Shared resources are put into shared folders
Importing any resource from anywhere is disallowed, as doing so can break the integrity of the fractal tree. The location of any file unambiguously communicates the limits of its use.
If the logic of any file (i.e. ‘mini-library’) is shared between multiple sub-trees, this ‘mini-library’ is moved from its original location to path/to/common-parent/shared/. Its new location may be a few directories up from where resources are used, provided shared/ is located as deep in the tree as possible.
We can think of each shared/ folder as a lightweight node_modules/ folder wherein each ‘package’ is a single file, instead of a folder as with package.json.
‘Mini-libraries’ like path/to/shared/a.js and path/to/shared/b.js can independently move between shared/ folders within the fractal tree based on their current usage.
Moving a ‘mini-library’ requires updating import paths, but this can be fully automated in most modern code editors, and linting helps ensure that the result of these operations are valid. Changing the physical location of a sub-tree does not discard its git blame.
Consistent with the rest of the tree, files like path/to/shared/a/x.js are considered ‘private’ and cannot be imported from anywhere except path/to/shared/a.js. To expose symbols from path/to/shared/a/x.js, they should be re-exported from path/to/shared/a.js
A shared ‘mini-library’ can import from any sibling files. For example, path/to/shared/a.js can contain an import from path/to/shared/b.js using the import path ("./b.js"). This is equivalent to importing one npm package from another.
The contents of the shared folders closer to the tree root are also accessible, but not the other way around. import { a } from "../../../shared/a.js" is allowed just as import { a } from "./shared/a.js", but import { a } from "./some/sub/tree/shared/a.js" or import { a } from "../../some/sub/tree/shared/a.js" are not.
Rule 7: Multiple entry points are allowed
A simple project like an npm package or an SPA starts with a single file, e.g. main.js. This file acts as the sole entry point into the entire fractal tree, which can be of any size.
If necessary, however, multiple entry points can be supported to accommodate things such as Next.js pages, executable CLI scripts, and test files. The locations of these additional entry points should be determined by their usage, but fractal rules still apply.
Just like ‘mini-libraries’, tree entry points can share resources with one another by importing them from **/shared/*.js.
When supporting multiple entry points, try to keep their names distinct from the ‘mini-libraries’ of the fractal tree. This can be achieved through file name suffixing: e.g. dashboard.page.jsx; signin.handler.js; do-something.script.js; foo.test.js.
Rule 8: Co-locate unit tests with covered files
To cover path/to/foo.js with unit tests, create path/to/foo.test.js. Placing unit tests into subfolders (e.g. path/to/__test__/foo.test.js) makes it harder to sync tests and see what files have tests.
If foo.test.js becomes too big, explore writing tests for individual ‘mini-libraries’ in path/to/foo/ instead, potentially allowing for simplification of the logic in the original foo.test.js file.
Higher-level integration, system, or end-to-end tests that cover a whole project (i.e. a library or an app) should be placed outside of the root of the source tree, and form their own independent ‘fractal forest’.
Rule 9: Exceptions are undesired but are not prohibited
The above rules are there to organize complex projects, but they don’t require an exhaustive opt-in. A fractal tree structure may be adhered to only in selected parts of a codebase, in part or whole, and gradually migrated to over time.
The easiest way to start organizing existing files is to start from the ‘leaves' and gradually move towards the ‘root’ of a repo or a yarn workspace.
Even with imperfect wiring between certain imports and exports, partial adoption of fractal tree structuring can provide benefits, making it easier to reason about dependencies within different parts of a codebase and unambiguously communicating structure without the need for individual READMEs and inline comments.
Walk-through
To understand how the rules apply, let’s create a new project that consists of a single file 🌱
hello.js
Imagine this file exports a variable named hello and also contains a private calculateX helper function that is used inside hello.
If the file becomes too big or if calculateX needs unit testing, we can extract this helper function into its own file:
hello.js
hello/
├╴ calculate-x.js
╰╴ calculate-x.test.js (optional)
Putting calculate-x in hello subfolder signals that the new file can only be used inside hello.js. If we add another ’private’ piece of logic for hello.js, (e.g. calculate-y), it also gets placed inside the same folder:
hello.js
hello/
├╴ calculate-x.js
╰╴ calculate-y.js
By convention, only hello.js is allowed to import from calculate-x and calculate-y.
Now imagine that we want to introduce a new function called doCommonThing(), and a separate new concept named bar, which will be used inside both calculateX() and calculateY(). Based on where these new resources are used, they belong in hello/shared/:
hello.js
hello/
├╴ shared/
│ ├╴ bar.js
│ ╰╴ do-common-thing.js
├╴ calculate-x.js
╰╴ calculate-y.js
Let’s assume that doCommonThing has an internal function a that would benefit from its own unit tests for confidence. We get:
hello.js
hello/
├╴ shared/
│ ├╴ bar.js
│ ├╴ do-common-thing.js
│ ╰╴ do-common-thing/
│ ├╴ a.js
│ ╰╴ a.test.js
├╴ calculate-x.js
╰╴ calculate-y.js
Finally, let’s imagine that we’ve introduced another entry point called hi.js which depends on the concept of bar, but does not use calculate-x, calculate-y or do-common-thing. In this case, hello/shared/bar.js is moved closer to the root of the tree, and into a new shared folder. Import paths are updated accordingly.
shared/
╰╴ bar.js
hello.js
hello/
├╴ shared/
│ ├╴ do-common-thing.js
│ ╰╴ do-common-thing/
│ ├╴ a.js
│ ╰╴ a.test.js
├╴ calculate-x.js
╰╴ calculate-y.js
hi.js
At each moment in time, files and folders communicate the ‘current truth’ of the relationship between various parts of the codebase. This ability is preserved with scale. 🌳
Examples of fractal tree structuring
Co-existing with Rust in a monorepo
Our fractal tree approach applies only to the JavaScript portion of our monorepo. Not all rules hold in Rust. Key differences in our Rust code include:
- P4. resources of a sub-sub-tree are inaccessible
- Rule 2: no
indexfiles are used (we tried this, but found it more distracting and a worse developer experience than simply just usingmod.rs) - Rule 5: imports within sub-trees do not use relative paths (given increased refactoring costs, and by default imports are absolute in Rust with the exception of reexporting sub-module exports)
- Rule 6: we don't have a shared folder in Rust, and we want to avoid having one
- Rule 7: multiple entry points are disallowed (our entry point is
fn main()- always) - Rule 8: unit tests are typically colocated at the bottom of files inside of a
testmodule, per Rust convention - Rule 9: exceptions are in fact prohibited; the
panic!macro is avoided
Get new posts in your inbox
Get notified when new long-reads and articles go live. Follow along as we dive deep into new tech, and share our experiences. No sales stuff.