Real-time collaboration across arbitrary blocks
Facilitating multiplayer interactions within novel, unrecognized UI components
July 21st, 2023



The rich collaborative editing space has seen a great amount of advancement lately, with projects like Yrs and Automerge moving towards more efficient data structures with impressive performance gains. Our initial graph backend lacked certain functionality that made it well-suited for real-time, collaborative user interfaces, but we’ve recently addressed these in a number of ways, and have developed a standalone new Proof-Of-Concept (documented here) which looks at where things might go next. In this post we look at how collaboration fits into the overall system we already have in place and what pieces require further work.
Setting the scene
HASH provides a way for users to create pages and add content in the form of blocks. Blocks receive data with a defined structure declared according to the Block Protocol Type System, and are transmitted to the blocks in a graph structure. In our initial implementation, pages wouldn’t update in real-time - but instead polled for new content. This meant a user could open the same page in multiple tabs and not notice the contents slowly drifting apart. Most modern applications face similar challenges of data synchronization, and therefore it is not a particularly novel problem, but it is a difficult one.
Such issues are amplified when multiple users may be on the same page at the same time, each editing and creating diverging page contents. Since these pages were to begin with saved in users’ clients before being synced back up, you’d start seeing strange intermediate updates on the page’s history as users would push updates that overwrote each other’s work… not desirable!
Our initial attempt to migrate away from polling and solve this problem involved implementing collaborative editing of the sort showcased by Marijn Haverbeke, the creator of ProseMirror, which is the rich-text editing library we use. This approach led to a number of technical challenges:
- accurately translating between the editor representation and our data representation,
- tight coupling between the frontend interface and the strategy to apply updates, and
- lack of support for collaborative editing of non-page data in the HASH user interface.
ProseMirror relies on representing data as a page containing blocks with attributes, which meant our collaborative editing translated back and forward between an internal graph representation and a document view.
This “collab” service relied on a real-time update stream that we simply called “realtime”, which contained updates from our PostgreSQL database’s Write Ahead Log (WAL), and was decoupled from our backend API. This realtime service remains a useful abstraction for us to have built in support of current and future collab work, as it allows hooking into an up-to-date change stream that shows the current state of the world to consumers.
However, with our experiments documented here, we intend to move away from page-oriented collaboration to a more generalized approach to facilitating collaboration arbitrarily across HASH, enabling any part of the system to subscribe to and publish updates without knowing about the implementation details of the user interface.
Since blocks in HASH are represented by entities contained in a page, modeling the underlying entities for collaboration would enable blocks to be arbitrarily collaborative as well. Blocks are sets of properties in a JSON object that are rendered within a UI component. If the underlying properties are able to be translated into a representation that allows for simultaneous editing, we’d allow HASH to provide a rich, realtime collaborative block experience.
Generalized Collab
To provide a more generalized collaboration service, we considered the different requirements we’d like to meet with the new iteration of Collab. The main pain points outlined above lead to the following list of requirements:
- Multiple users can edit the same subgraph (for example a page is a subgraph).
- Updates to the subgraph are saved to the Graph as soon as possible.
- When entities in the subgraph are updated by a non-frontend client (e.g. a scheduled process) they are updated in real-time through Collab for all subscribing consumers.
- Individual changes are correlated to users and persisted with every update (provenance information is kept).
- The system should be horizontally scalable.
- The system should be extensible.
- Conflicts are handled ‘gracefully enough’ without breaking the collection of entities or producing inconsistent user views (some manual conflict resolution is okay).
- Updates are perceived as “fast”, taking 100 ms or less for updates to propagate.
- Changes can be rolled back and forth (undone/redone).
- Possibility for offline edits in the future (supported by a bi-temporal datastore).
The list is quite ambitious with the biggest unknown being how we would model subgraphs efficiently within a collaboration service. Subgraphs can span over multiple, overlapping but non-equivalent subgraphs which means we would need a way for entities to be part of several disjoint groupings.
Using a simple conceptual framework of making changes to entities in a pub/sub model, we came up with the following general flow of data for Collab. The frontend (or any other consumer of HASH) subscribes to a logical grouping of entities (a subgraph). Consumers publish updates to entities which are part of that grouping. Collab applies changes in the order that they were received and serializes writes to the Graph to ensure that the entity is always consistent and contains appropriate provenance metadata. The consistency of an entity relates to having a single writer that doesn’t jumble the entity with incorrect intermediate states. The entities Collab manages are analogous to entities in our Graph and should be trivial to write back to the Graph.
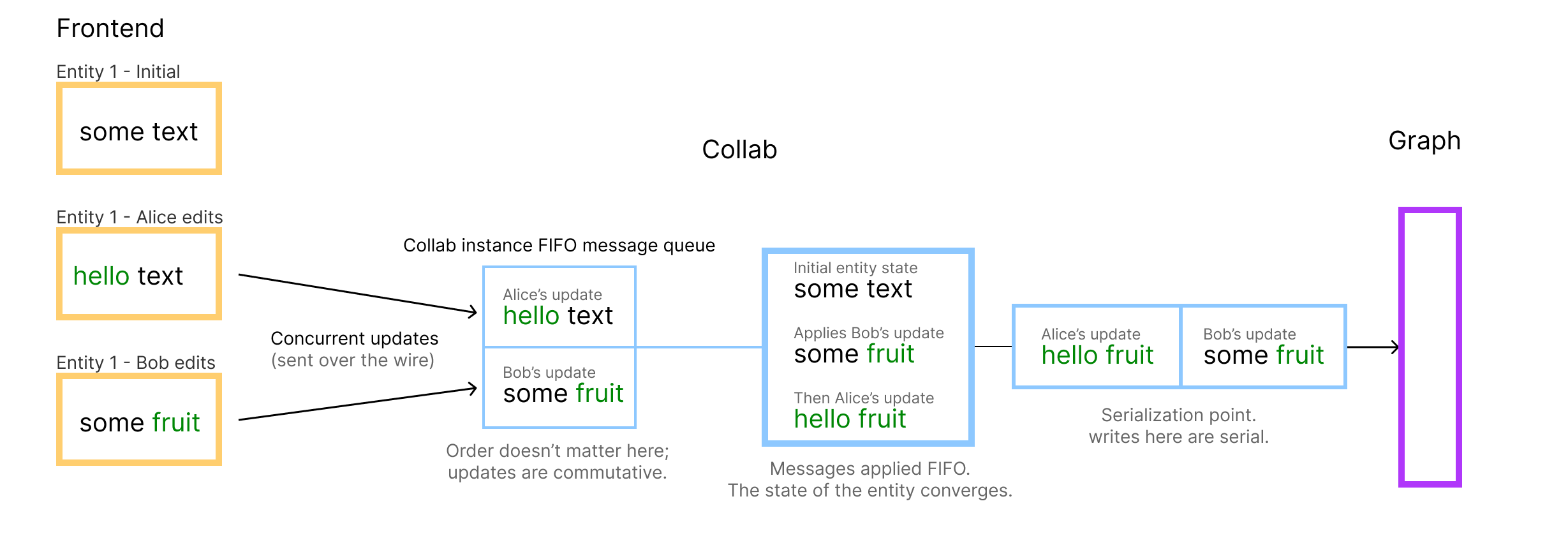
To allow for full-featured real-time collaboration, a simple First in, First out (FIFO) queue to apply updates wouldn’t suffice, but it would allow us to test out the idea and incrementally replace the underlying update handling with more sophisticated algorithms and data structures such as Operational Transformation or CRDTs to allow updates to be commutative (i.e. allowing them to be applied in any order). Using some common update format, such as JSON Patch or more specialized Yjs updates, we’ll be able to interact with entity updates consistently with any API consumer. JSON Patch can for example be the foundational update format for allowing CRDT implementations similar to https://github.com/streamich/json-joy to be used within the system.
The Collab service should notify all peers of any changes made to an entity, using the same data format as incoming updates. This ensures that all users have a consistent view of entities. The inner workings of applying changes to an entity in FIFO order should be encapsulated by the addressable entity pool seen in Figure 2.
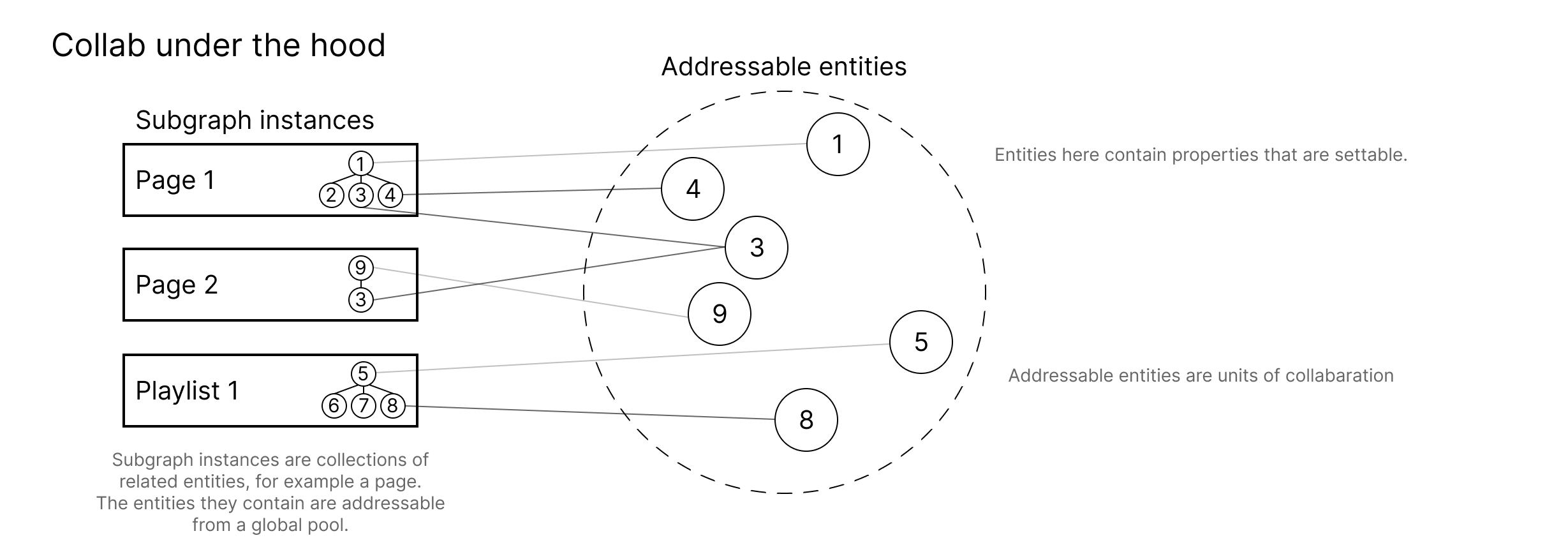
Figure 2: A diagram showing how subgraph instances operate on a shared entity pool
Users on Page 1 are able to subscribe and publish changes to the entity present in Page 2, and these changes can be shared across multiple subgraph instances which in theory could span multiple kinds of subgraphs such as Pages, Playlists, Tables, etc.
The setup lends itself well to be modeled as a collection of workers communicating with messages as entities can be self-contained and only speak to the outside world via messages. Allowing the entities to be a self-contained unit means we can have one big pool of nano “servers” that can receive requests and provide responses to updates. This inspired us to try Elixir and the Erlang VM for the initial Proof of Concept.
The PoC (which we’ll now showcase in just a second) experiments with validating the addressable entity space and potential to scale along with a handful of the requirements. It was important for us to optimize any trade-offs we’d face with the system and pave a clear road for how the service can evolve with our expectations and changes to our requirements.
The Proof of Concept
Our new-system PoC is written in Elixir, and allows publishing/subscribing to entities. We aimed to create an initial system that could address our aforementioned requirements 1 through 6. In the PoC, changes to the entities are expressed with JSON Patch, and a WebSocket server exposes the underlying system primitives (subscription and publishing patches). The PoC is missing the logical grouping of subgraphs, but that was assumed to be a lesser missing piece compared to the initial addressable entity space.
The system is distributed using built-in BEAM primitives (Processes and Process groups) and abstractions for managing the system’s topology. A process is an Erlang VM primitive more similar to a self-contained green thread than an OS process, which we use to model entities. Instances of the application form a cluster, where each Graph entity has a corresponding entity process that is distributed using consistent hash-rings managed by https://github.com/bitwalker/swarm.
Swarm also provides ways to balance processes when the topology changes, such as migrating processes from one node to another, or fuse multiple nodes together in response to topology changes.
The underlying JSON Patch logic is implemented in Rust using Serde and a JSON Patch crate, all automatically linked to the Elixir project with bindings provided by https://github.com/rusterlium/rustler. The PoC should show the strengths of the BEAM and the ease of interoperability with native code allowing us to incrementally add the features we require.
The Processes
The system is built on processes that can be distributed across a cluster, and transparently addressed as if they were local to the nodes. Instead of using a subgraph as the logical grouping, which the full implementation would require, the PoC uses a WebSocket connection process to subscribe to entity processes. For example the WebSocket handler websocket-1 can subscribe to changes on entity-1 and entity-2 (both local to the handler), while another WebSocket connection websocket-2 on a separate node may (remotely) subscribe to entity-2 and locally subscribe to entity-3.
From the perspective of the WebSocket connections, all processes are node-local and messages are automatically routed where they should be by the BEAM/Swarm without manual intervention and routing logic.
The entity processes are distributed on the nodes using a consistent hash-ring that will consistently and predictably delegate entities on nodes. This is handled by Swarm and not developed as part of the PoC code. The entity and WebSocket routing can be found in the GitHub project accompanying this blog post.
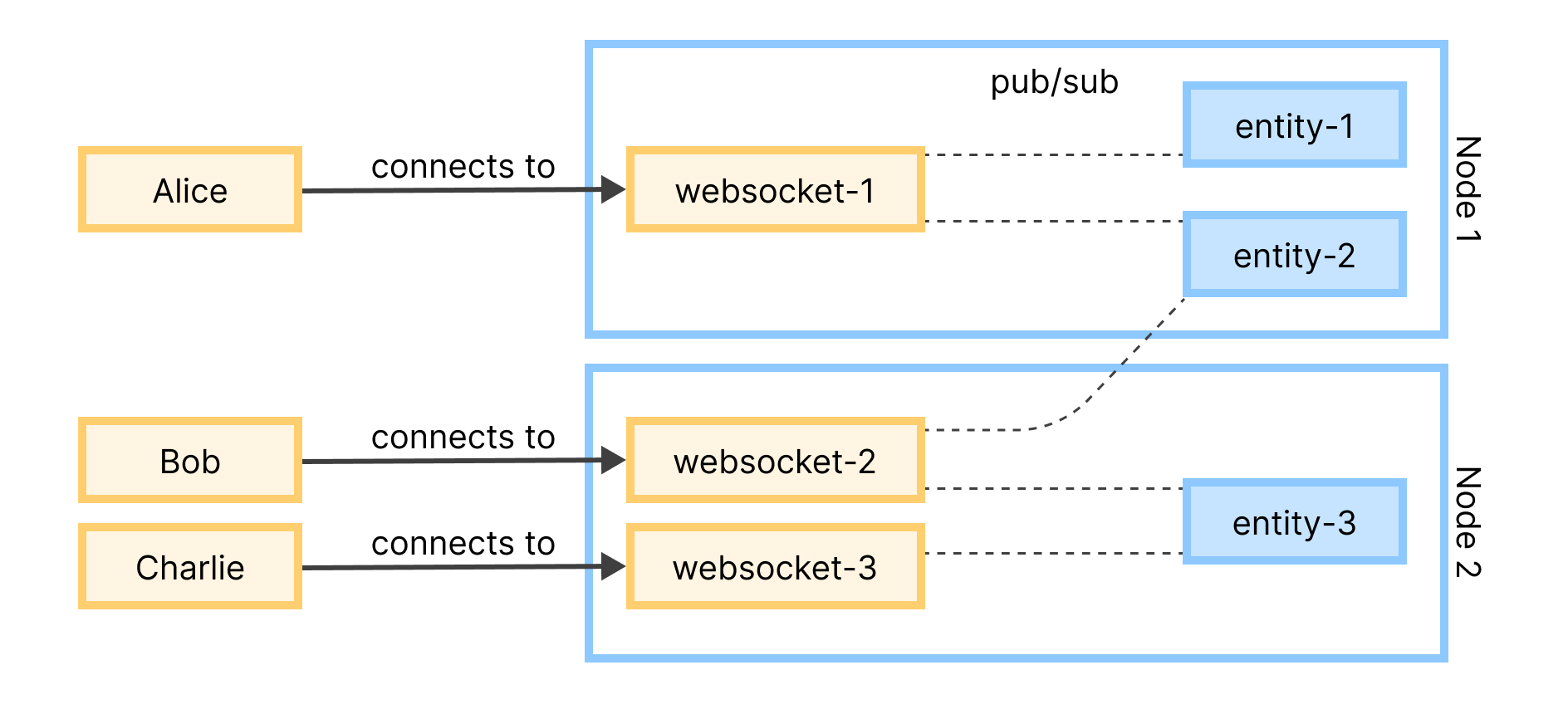
Figure 3: A diagram showing users' websocket connections to nodes
The main pieces plumbing the WebSocket instances and entities together is Phoenix PubSub. This choice was made for its simplicity, but could be replaced with other transports if required.
Each entity process initializes a new JSON Value in Rust which is stored as a reference in the process. All updates passed to the entity process route down to Rust using this reference. The entity process can schedule a Graph write after the update has been applied to the in-memory representation.
A WebSocket connection is also a process in the system and subscribes to all relevant PubSub changes for the collection of entities it is interested in knowing about (i.e. the entities residing in its subgraph(s) of interest). The list of entities is not static and can be updated if the subgraph were to expand or reduce in size.
The following code snippet shows how updates are applied in the entity process followed by a broadcast to all listeners. Any errors are ignored for now.
@impl true
def handle_cast({:apply_update, pid, raw_message}, state) do
new_state =
Map.update!(state, :json, fn current_state ->
case CollabNative.apply_patch(current_state, raw_message) do
{} ->
entity_id = state[:entity_id]
PubSub.broadcast_from!(
:pubsub,
pid,
entity_id,
{:publish, raw_message}
)
current_state
{:error, val} ->
Logger.info("Got patch apply error #{inspect(val)}")
current_state
end
end)
{:noreply, new_state}
end
The process is modeled as GenServer (a generic server process) that will pick messages off its own mailbox sequentially. The implementation detail of the patch is handled by the native Rust code, and delegated through the CollabNative module to Rustler bindings.
The system can be showcased in a simple JavaScript demo. Try modifying the text areas (write any valid JSON in any of the Peer text areas and press CTRL/CMD + s) and observe how the changes are propagated between the peers. The ordering of operations is predictable, and you’ll be able to inspect how the entity process JSON State changes over time, and what kind of JSON Patches are required to send diffs down to peers.
Peer 1
Peer 2
Peer 3
Entity 1
Addressable entity space
The sequential nature of how the processes handle messages allows the system to be intuitive in how it operates, allowing us to focus on update processing rather than distribution and routing of updates. Essentially we hand over the intricate data coordination to the Erlang VM.
The Elixir PoC code allows for users to edit the same entities and provides affordances for writing changes back to our Graph with provenance. Any writes that come from “external” providers that update the Graph directly can be republished in Collab as if they were a Collab change through the Realtime change stream. Although integration with the Realtime service’s change stream isn’t implemented yet, the system is set up in a way that allows for the Realtime change stream to be plugged into the entities and apply updates down the line.
The Elixir code is to be responsible for fulfilling the first six requirements. With incremental changes to read from the realtime change stream and writing to the graph backend, we should have a scalable platform for collab. Erlang’s concurrency primitives help with scalability and Elixir’s focus on developer experience and tooling help make the system extensible - which should appropriately address the fifth and sixth requirement.
Native Rust code
Each entity process handles its own JSON object that can be patched using JSON Patch. The underlying storage and patching happens through a rather small Rust module that uses Serde and a JSON Patch crate.
The code itself exposes the JSON object as an opaque memory reference to the entity process. This reference can be used to make updates to the underlying JSON object using whatever functions are exposed. What this shows is that we are able to implement complex logic and data structures that do the heavy computational work while the BEAM handles the I/O.
#[rustler::nif]
fn apply_patch(json_string: ResourceArc<JsonString>, json_patch_string: &str) -> Result<(), Error> {
let entity_patch: EntityUpdate = serde_json::from_str(json_patch_string).map_err(|_e| {
Error::Term(Box::new(atoms::json_deserialize_error()))
})?;
let mut json_string = json_string.as_mut();
patch(&mut json_string, &entity_patch.patch)
.map(|_| ())
.map_err(|_| Error::Term(Box::new(atoms::malformed_patch())))
}
This code snippet shows how an opaque JSON String reference and a JSON Patch string can be given to the Rust library to apply the JSON Patch, mapping any errors and providing seamless interoperability across the two ecosystems.
All resources passed to Elixir from Rust are reference counted to ensure appropriate ownership semantics of the underlying resources and to make sure resources are safely dropped once no process holds a reference to them.
This part of the PoC provides affordances for allowing the system to handle conflicts gracefully, efficiently applying updates and enables future work for advanced features including offline editing and undo/redo history - the remaining four requirements.
Future work
Using Conflict-free Replicated Data Types (CRDTs), such as those provided by Yrs, would provide a broader set of features compared to using JSON Patch and JSON.
CRDTs are data structures geared towards reconciling conflicts in distributed systems and multi-user applications, which can allow updates to commute. While CRDTs might be seen by some as overkill when a central server exists that serializes writes, can provide coordination, and act as a source of truth… one major advantage is that we can more easily support offline editing down the line, as CRDTs can apply updates in an out-of-order fashion, allowing changes made while offline to be published when network connections are reestablished. For the PoC, we can imagine that the entity JSON value can be substituted with a Yrs CRDT along with changing clients/supporting Rust code to use Yrs updates rather than JSON Patch.
In addition to CRDTs, another possible solution is Operational Transformation (OT). OT algorithms are used to synchronize document updates between multiple users in many real-time collaborative editing applications, such as Google Docs. OT is a more mature technology than CRDTs, but requires a centralized source of truth, and thus we consider it less appropriate given our complete original set of aims.
Making best-use of the new collaboration service will require changing how updates are sent from the frontend, which is governed by the Block Protocol specification. To enable collaborative editing and not just ‘last write wins’ we need to move away from entity updates being sent as entire property objects, to much more granular expressions of how individual property values should be amended, which can be combined and any conflicts resolved intelligently in producing the new value. This might involve different data update formats depending on the data type: some might have more intricate representations than others. A good user experience for collaborative editing will be particularly important for rich text and canvases, for example.
Optimizing the system and weighing trade-offs are also important future considerations. This includes looking at the performance and scalability of the system, as well as potential issues with conflict resolution and data consistency. Collab would be mirroring the state of the graph, and potentially introducing points of failure/data corruption, so ideally there would be specialized testing in place to ensure our setup is functioning as expected across the systems.
Since collab would be a way for consumers of the graph to gain a real-time view of graph updates, the communication protocol and transport layer has to take into account that we may want other services than the frontend consuming data. Which transport and protocol to use for consumers is still an open question, and one we’re interested in being as flexible as possible, and ideally strongly typed to allow for automatic client generation.
The current PoC doesn’t take links between entities into account, which is an essential part of the data model in HASH. Links would need to be carefully handled and implemented as part of the system as a first-class citizen to allow for conflict resolution and distribution of edits to links between entities, as well as the content of entities themselves. Links come with their own set of complexities which are out of scope for this blog post.
Conclusion
This blog post has explored how we can bring real-time capabilities to HASH through a collab service. We’ve outlined the main technical design decisions, and explored a PoC to validate feasibility of the design. While it requires further work to be made usable, we’re excited about the possibilities that a revamped collab solution will bring to HASH, and we hope that the information presented in this post helps others considering similar designs.
The source code for the PoC collab service discussed in this post is open-source, and freely available on our GitHub.
Get new posts in your inbox
Get notified when new long-reads and articles go live. Follow along as we dive deep into new tech, and share our experiences. No sales stuff.